Is there a legit or a hacky way to override or "fast-forward" value of @@DBTS in SQL server?
The only way I was able to do it is to do some dummy updates to a table that has a timestamp / rowversion column in a loop, where one loop step is like:
SELECT @@DBTS -- original value
-- no-op update that increments @@DBTS nevertheless
UPDATE Table_with_a_rowversion_column SET any_other_column = any_other_column
SELECT @@DBTS -- value has incremented by a number of rows in Table_with_a_rowversion_column
I don't like this because it's slow and takes resources. I want to increment @@DBTS by many billions and do it fast - as much as 16^9. My loop script did less than 16^8 of incrementing in 30 minutes, so it'll take at least 8 hours.
Background / why anybody would want to do that?
I'm migrating data from database 1 to database 2. They have different schemas, but both 1 & 2 have a "state" table (about a million of rows) and a "state_history" table (10's of millions rows).
state table has a rowversion column.
trigger on state table inserts pre-update data into state_history table (subject to some filtering) - including captured rowversion value (saved as binary(8))
union of state and state_history sorted by the rowversion/binary(8) column is the only reliable way to sort latest & historical values in the order they actually occurred (captured system clock is not always reliable).
I want to keep same monotonically increasing rowversion invariant in target database 2, few parts of the system rely on this invariant.
I do have control over historical rowversions because it's binary(8) but they range from as little as 16^5 to as much as 16^9 i.e. there`s no large base value to subtract so I have to keep them as is.
But I don't have any control over the main target state table - SQL inserts small rowversion values based on target database's @@DBTS. I wish I could simply tell it to override it to 16^9 and then run my migration script.
CodePudding user response:
There is sort-of an easy win. @@DBTS will update for INSERTs and it's not unique to real tables. The following code makes a dummy table and then inserts a (binary) BILLION rows in 3 minutes flat on my laptop. To change the value by 16^9, it will take 64 iterations of the Truncate/Insert section and 64*3.2 is "only" 204.8 minutes (3.413) hours and, when it's all done, your log file will still be small and your PRIMARY filegroup will not have grown at all.
Note that you need to be in either the BULK_LOGGED or SIMPLE Recovery Model when you run this or it will seriously explode your T-Log File. The resulting HEAP will be 18.75GB in size but it only uses 450MB (not a misprint... Megabytes) of T-LOG.
Details are in the comments. READ THE COMMENTS! THEY'RE IMPORTANT!
--===== IMPORTANT! CHANGE ALL OCCURANCES OF THE WORD "SCRATCH" TO THE NAME OF THE DATABASE YOU WANT TO DO THIS IN!!!
-- ALTHOUGH I"VE NOT TESTED FOR IT, I'M PRETTY SURE IT'S GOING TO KNOCK A FAIR BIT OUT OF BUFFER CACHE, NO MATTER WHAT!
-- READ AND UNDERSTAND ALL THE COMMENTS IN THE CODE BELOW OR DON'T USE THIS CODE!
-- TEST IT ON A DEV BOX FIRST!!!
--===== Create a temporary filegroup and presized file so we don't have to wait for growth.
-- Yes... the table (HEAP) will reach a size of 18.75GB (aka 18750MB)
USE Scratch;
ALTER DATABASE Scratch ADD FILEGROUP Dummy;
ALTER DATABASE Scratch
ADD FILE (NAME = N'Dummy'
,FILENAME = N'E:\SQL Server\SQLData\Dummy.ndf'
,SIZE=18750, MAXSIZE = 20000MB, FILEGROWTH=50MB)
TO FILEGROUP Dummy
;
GO
--===== This creates a table with the minimum row width we can get away with.
CREATE TABLE dbo.Dummy (N TINYINT, ts TIMESTAMP) ON Dummy; --It's a HEAP, actually
GO
--===== Do a (binary) BILLION inserts into this working table to increase @@DBTS by 1 BILLION (1024^3) for the database.
-- You could put this in a loop. The file will not grow and we'll do minimal logging to protect the logfile.
-- TO GET THE MINIMAL LOGGING, THE DATABASE MUST BE IN THE BULK LOGGED OR SIMPLE RECOVERY MODEL.
-- OTHERWISE, THIS WILL EXPLODE YOUR LOG FILE.
-- On my laptop, this section takes 3.2 minutes to run and only uses 450MB thanks to minimal logging.
-- And, no, that's not a misprint... ONLY 450 Megabytes of log file useage
TRUNCATE TABLE dbo.Dummy; --Only Page De-Allocations are logged and required to continue minimal logging.
CHECKPOINT; --Forces writes to T-Log file in the BULK LOGGED and to clear in the SIMPLE Recovery Models.
CHECKPOINT; --Sometimes, one CHECKPOINT isn't fully effective.
;
SELECT @@DBTS --Just checking the "Before" value.
;
WITH
E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1))E0(N)) --Up to 16 rows
INSERT INTO dbo.Dummy WITH (TABLOCK) --Required to get minimal logging in BULK LOGGED and SIMPLE Recovery Models
(N)
SELECT TOP 1073741824 CONVERT(TINYINT,1) --Binary BILLION (1024^3)
FROM E1 a,E1 b,E1 c,E1 d,E1 e,E1 f,E1 g,E1 h --Up to 16^8 or 4,294,967,296 rows
OPTION (RECOMPILE,MAXDOP 1) --Helps minimal logging and prevents parallelism for a substantial speed increase.
;
SELECT @@DBTS
;
GO
--===== This is the cleanup of the file and filegroup, which is MUCH faster than a SHRINK.
DROP TABLE dbo.Dummy;
ALTER DATABASE Scratch REMOVE FILE Dummy;
ALTER DATABASE Scratch REMOVE FILEGROUP Dummy;
CHECKPOINT; --Forces writes to T-Log file in the BULK LOGGED and to clear in the SIMPLE Recovery Models.
CHECKPOINT; --Sometimes, one CHECKPOINT isn't fully effective.
GO
SELECT @@DBTS --Verify that the effort wasn't wasted.
;
Here's a picture of the Scratch database I used. It started out at 50MB with a growth of 50MB for both files during my initial testing to see what the ultimate size would be. You can see that the PRIMARY file group didn't grow much (it's only 4MB and started at 1MB). Everything we did went to the DUMMY file group, which we're going to drop when we're done so we don't have to SHRINK our PRIMARY or otherwise worry about the extra 18.75GB we just used.
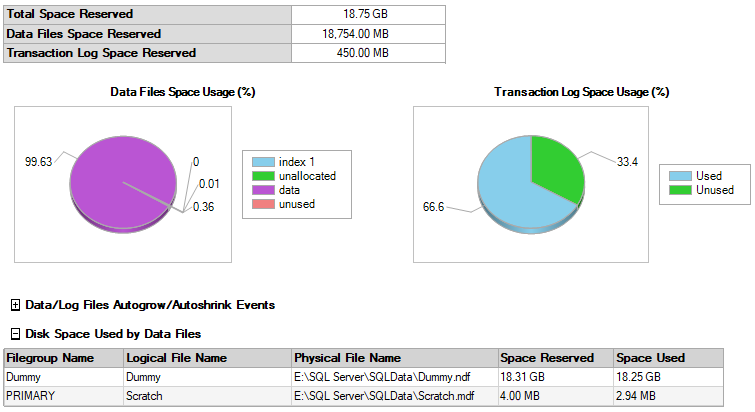
After we run the last bit of code above to drop the DUMMY table, remove the DUMMY file, and remove the DUMMY file group, the total data file size is back to normal without having to do a SHRINK.
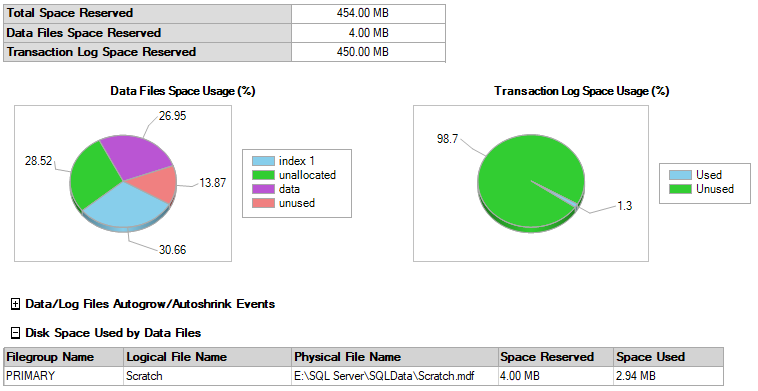
And, if there was only 450MB available in the log file, it wouldn't have grown at all.