I have a Dataframe as follow. Column "b" of the DataFrame has string value with maximum of 5 numbers. So, I want to consider the missing values in the rows which they has less than 5 numbers. For example, the second rows has 2 numbers, I fill the row with mean of 4 and 6. And also for the third row, I want the same thing.
import pandas as pd
df = pd.DataFrame()
df['a'] = [ 1, 2, 3 ]
df['b'] = [ '2, 3, 4, 5,6' , '4,6', ' 6,8']
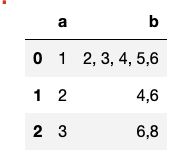
I here is the DataFrame which I want.
CodePudding user response:
Here's one approach:
Splitting on comma and expanding creates a DataFrame; then mask the rows with NaN values and fill them with the mean:
tmp = df['b'].str.split(',', expand=True).astype(float)
df[[f'b{i}' for i in range(1,tmp.shape[1] 1)]] = (tmp.mask(tmp.isna().any(axis=1))
.T.fillna(tmp.mean(axis=1)).T
.astype(int))
df = df.drop(columns='b')
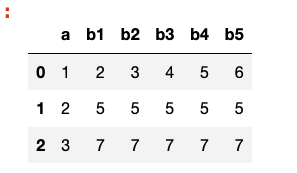
Output:
a b1 b2 b3 b4 b5
0 1 2 3 4 5 6
1 2 5 5 5 5 5
2 3 7 7 7 7 7
CodePudding user response:
we apply eval to column b, replace short tuples with tuples of size 5 filled with averages, expand into columns and rename columns
df2 = (df['b'].apply(eval)
.apply(lambda t: t if len(t)==5 else (sum(t)/len(t),)*5)
.apply(pd.Series)
.rename(columns = lambda n:f'b{n 1}')
)
we then join it to the original column a
df[['a']].join(df2)
output:
a b1 b2 b3 b4 b5
0 1 2.0 3.0 4.0 5.0 6.0
1 2 5.0 5.0 5.0 5.0 5.0
2 3 7.0 7.0 7.0 7.0 7.0