I have this dataframe:
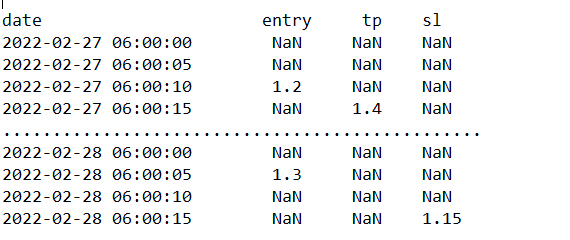
I need to perform some addictions and substractions based on conditions.
If we first have a non-NaN value in the tp, then do this: tp-entry
if, instead, the first non-NaN value is contained inside "sl" column, then do this sl-entry.
We will store these values inside a new column called "pl", so the final datafram will look like this:

I tried (with no success) this (reproducible code):
tbl = {"date" :["2022-02-27", "2022-02-27", "2022-02-27", "2022-02-27", "2022-02-28",
"2022-02-28","2022-02-28", "2022-02-28"],
"entry" : ["NaN", "NaN", 1.2, "NaN", "NaN", 1.3, "NaN", "NaN"],
"tp" : ["NaN", "NaN", "NaN", 1.4, "NaN", "NaN", "NaN", "NaN"],
"sl" : ["NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", 1.15]}
df = pd.DataFrame(tbl)
df.sort_values(by = "date", inplace=True)
df['pl'] = np.where(df["entry"]) #i don't know how to continue...
Any ideas? Do you know better way?
Edit
In the photo entry-sl is wrong, I need sl-entry
CodePudding user response:
IIUC, you can combine "tp" and "pl", then bfill per group. Also bfill "entry" per group. Then assign the difference only on the first (i.e. non duplicate) row per date:
group = df['date']
s1 = df['tp'].fillna(df['sl']).groupby(group).bfill()
s2 = df['entry'].groupby(group).bfill()
df.loc[~group.duplicated(), 'pl'] = s1-s2
NB. if you really have dates with times, use instead as group:
group = pd.to_datetime(df['date']).dt.date
output:
date entry tp sl pl
0 2022-02-27 NaN NaN NaN 0.20
1 2022-02-27 NaN NaN NaN NaN
2 2022-02-27 1.2 NaN NaN NaN
3 2022-02-27 NaN 1.4 NaN NaN
4 2022-02-28 NaN NaN NaN -0.15
5 2022-02-28 1.3 NaN NaN NaN
6 2022-02-28 NaN NaN NaN NaN
7 2022-02-28 NaN NaN 1.15 NaN