I want to shift the number of orders by in range from 1 to 7. Here is my python code :
def make_features(data, max_lag):
for lag in range(1, max_lag 1):
data['lag_{}'.format(lag)] = data['num_orders'].shift(lag)
make_features(df, 7)
I try to do the same think in Pyspark : Code :
def make_features(data, max_lag):
for lag in range(1, max_lag 1):
data['lag_{}'.format(lag)] = data['num_orders'].shift(lag)
make_features(df, 7)
I get this error :
TypeError: 'int' object is not callable
Traceback (most recent call last):
TypeError: 'int' object is not callable
I also try this code :
for lag in range(1, 8):
window = Window.orderBy("date")
lagCol = lag(col("num_orders"), n).over(window)
df.withColumn(f"LagCol_{n}", lagCol)
This it just shift by 1 unit :
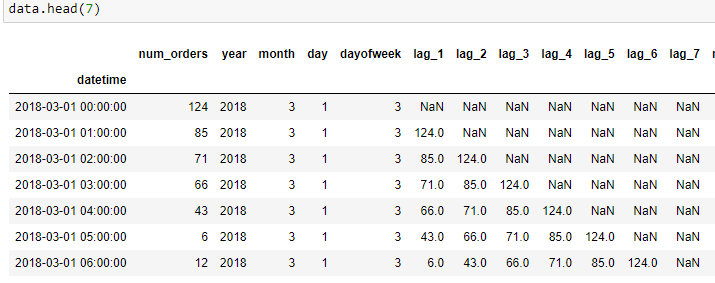
Expected result:
CodePudding user response:
In PySpark, there is no shift function as you expected, and you were in the right direction when using lag. But there is a little trick here when you have to do lag_2 based on lag_1 and so on.
from pyspark.sql import functions as F
from pyspark.sql import Window as W
df = df.withColumn('lag_0', F.col('num_orders'))
for lag in range(1, 8):
df = (df
.withColumn(f'lag_{lag}', F
.lag(f'lag_{lag - 1}')
.over(W
.partitionBy(F.lit(1))
.orderBy('date')
)
)
)
---- ---------- ----- ----- ----- ----- ----- ----- ----- -----
|date|num_orders|lag_0|lag_1|lag_2|lag_3|lag_4|lag_5|lag_6|lag_7|
---- ---------- ----- ----- ----- ----- ----- ----- ----- -----
| 1| 124| 124| null| null| null| null| null| null| null|
| 2| 85| 85| 124| null| null| null| null| null| null|
| 3| 71| 71| 85| 124| null| null| null| null| null|
| 4| 66| 66| 71| 85| 124| null| null| null| null|
| 5| 43| 43| 66| 71| 85| 124| null| null| null|
| 6| 6| 6| 43| 66| 71| 85| 124| null| null|
| 7| 12| 12| 6| 43| 66| 71| 85| 124| null|
---- ---------- ----- ----- ----- ----- ----- ----- ----- -----