I have a pandas dataframe with a few columns. I am trying to color the cells in one of the columns and I have been partially successful so far.
In the column color_me I want to:
- For all the rows but the last one, I will be coloring according to a specific scale
- In the last row of that column (therefore, just one cell), I want to color based on another scale. It is the 9th row of that column.
I was able to do 1., but I am failing to do 2. I don't know how to highlight just one specific cell if I have to put a conditional on which color it should be having.
df = pd.DataFrame({'metric': ['metric0', 'metric1', 'metric2', 'metric3', 'metric4', 'metric5', 'metric6', 'metric7', 'metric8', 'metric9'],
'column1': [80, 12, 110, 100.2, 39, 29, 48, 78, 93, 100.8],
'color_me': [89, 102, 43, 112, 70, 38, 80, 110, 93, 100.3]})
def highlight_SLA(series):
green = 'background-color: lightgreen'
yellow = 'background-color: yellow'
pink = 'background-color: pink'
return [green if value <= 90 else yellow if value <100 else pink for value in series]
def highlight_specific_cell(series):
green = 'background-color: lightgreen'
yellow = 'background-color: yellow'
pink = 'background-color: pink'
return [green if value >= 100.2 else yellow if value >100 else pink for value in series]
slice_SLA = ['color_me']
slice_SLA_index = ['color_me'][9]
(df.style
.apply(highlight_SLA, subset = slice_SLA)
.apply(highlight_SLA_availability_index, subset = slice_SLA_index)
)
The second apply doesn't work as I wanted. It is supposed to give a green background to the that has a value of 100.3.
Should I select its subset in another way? It seems that slice_SLA_index = ['color_me'][9] is not the way to do it, but I don't know how to fix this.
CodePudding user response:
The intent of the question is to code with the understanding that we want to set a special color as the background color only for specific rows of specific columns. For the columns that we pass the specific columns, we create a list of background colors by condition, create a blank series, and then set that color where we want it to be placed. Adapt that style to the data frame in the original. The original of this code was changed from this answer to a series to accommodate 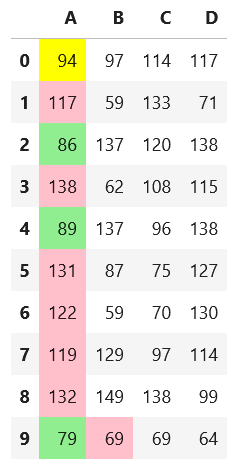
CodePudding user response:
The simplest way to modify only specific rows in addition to columns is to make the subset more restrictive by indexing both axes. The standard approach is to use an 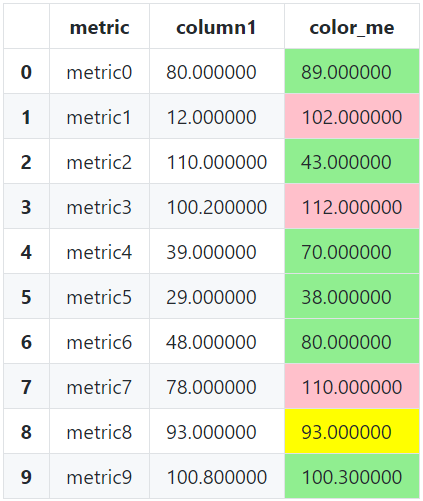
*Notice that index 9 color_me is green due to the highlight_specific_cell rules rather than pink (highlight_SLA) rules.
The subset can be modified using standard loc indexing rules. For example, rows 7-9 in column1 and color_me could be subset in the following way:
slice_SLA = ['color_me']
slice_SLA_index = pd.IndexSlice[7:9, ['column1', 'color_me']]
(
df.style
.apply(highlight_SLA, subset=slice_SLA)
.apply(highlight_specific_cell, subset=slice_SLA_index)
)
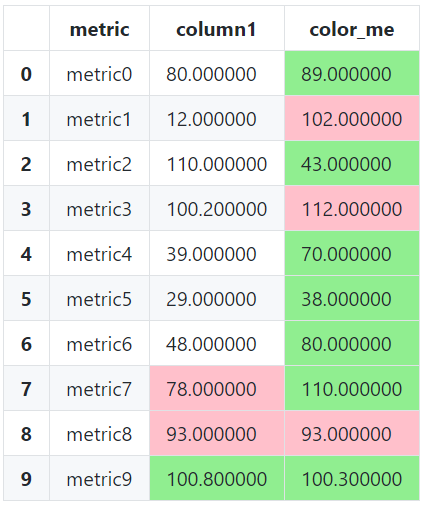
As a general improvement np.select is a more common solution to multi-condition mappings than a list comprehension:
import numpy as np
def highlight_SLA(series):
green = 'background-color: lightgreen'
yellow = 'background-color: yellow'
pink = 'background-color: pink'
return np.select(
condlist=[series <= 90, series < 100],
choicelist=[green, yellow],
default=pink
)
def highlight_specific_cell(series):
green = 'background-color: lightgreen'
yellow = 'background-color: yellow'
pink = 'background-color: pink'
return np.select(
condlist=[series >= 100.2, series > 100],
choicelist=[green, yellow],
default=pink
)