I'm attempting to clean up some data I've scraped into an excel page but I'm getting extra info and I'm wanting to clean it up a little can someone tell me how to determine what level I need to drop using pandas?
my code so far
soup1 = BeautifulSoup(driver.page_source,'html.parser')
df1 = pd.read_html(str(soup1))[0]
print(df1)
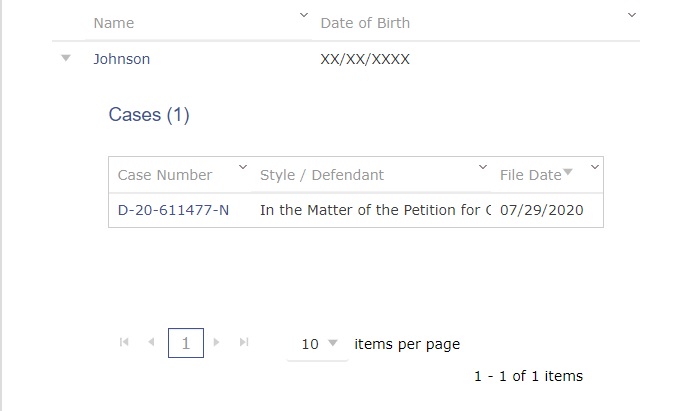
this pulls out the data below.

the info I need is in the red highlighted everything else is useless data I don't need.
I'm not sure if it's needed but the data is being pulled from this table.
CodePudding user response:
You may try : df=df.loc[df['Case Number'].notna() & (df['Case Number']!='Case Number')]
CodePudding user response:
First, you need to understand how a html tablet standard structure works, for example:
<table>
<tr>
<th></th>
</tr>
<tr>
<td></td>
</tr>
<tr>
<td></td>
</tr>
</table>
Now, you can use find_all method and find everything related to the table, but I think it is best to investigate the BeautifulSoup documentation and search the correct way to find the data in your table.
import pandas as pd
import requests
from bs4 import BeautifulSoup
def get_table(url):
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
rows = []
for child in soup.find_all('table')[4].children:
row = []
for td in child:
try:
row.append(td.text.replace('\n', ''))
except:
continue
if len(row) > 0:
rows.append(row)
df = pd.DataFrame(rows[1:], columns=rows[0])
return df
data = get_table('url')