I have a data frame where I need to show a totals in the last row in terms of the count of not null values of string value columns and a summation of a one column and the average of another column.
df2 = pd.DataFrame({ 'Name':['John', 'Tom', 'Tom' ,'Ole','Ole','Tom'],
'To_Count':['Yes', 'Yes','Yes', 'No', np.nan, np.nan],
'To_Count1':['Yes', 'Yes','Yes','No', np.nan,np.nan],
'To_Sum':[100, 200, 300, 500,600, 400],
'To_Avg':[100, 200, 300, 500, 600, 400],
})
This is how I code to get this result.
df2.loc["Totals",'To_Count':'To_Count1'] = df2.loc[:,'To_Count':'To_Count1'].count(axis=0)
df2.loc["Totals",'To_Sum'] = df2.loc[:,'To_Sum'].sum(axis=0)
df2.loc["Totals",'To_Avg'] = df2.loc[:,'To_Avg'].mean(axis=0)
However if I run this code again accidently the values get duplicated. Is there a better way to get this result.
Expected result;
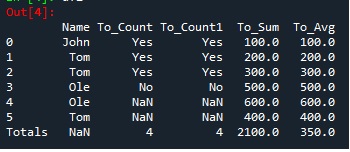
CodePudding user response:
Use DataFrame.agg with dictionary:
df2.loc["Totals"] = df2.agg({'To_Sum': 'sum',
'To_Avg': 'mean',
'To_Count': 'count',
'To_Count1':'count'})
print (df2)
Name To_Count To_Count1 To_Sum To_Avg
0 John Yes Yes 100.0 100.0
1 Tom Yes Yes 200.0 200.0
2 Tom Yes Yes 300.0 300.0
3 Ole No No 500.0 500.0
4 Ole NaN NaN 600.0 600.0
5 Tom NaN NaN 400.0 400.0
Totals NaN 4.0 4.0 2100.0 350.0
More dynamic solution if many columns between To_Count and To_Count1:
d = dict.fromkeys(df2.loc[:,'To_Count':'To_Count1'].columns, 'count')
print (d)
df2.loc[:,'To_Count':'To_Count1']
df2.loc["Totals"] = df2.agg({**{'To_Sum': 'sum', 'To_Avg': 'mean'}, **d})
print (df2)
Name To_Count To_Count1 To_Sum To_Avg
0 John Yes Yes 100.0 100.0
1 Tom Yes Yes 200.0 200.0
2 Tom Yes Yes 300.0 300.0
3 Ole No No 500.0 500.0
4 Ole NaN NaN 600.0 600.0
5 Tom NaN NaN 400.0 400.0
Totals NaN 4.0 4.0 2100.0 350.0