I am trying to use pandas to develop some trend data for a dataset I am working on. The set consists of a product number, fiscal year, and number of units sold. I want to create a fourth 'trend' column that will compare each product to itself by fiscal year, specifically the year before it. The first trend for each product should always be 0 since there is no data for the previous year. Trend is simply a " " if the value has gone up since the previous year for that product or a "-" if the opposite is true. I thought this was pretty straightforward but apparently I'm overlooking something.
data_out.sort_values(['product_number','fiscal_year'], inplace = True)
trend = []
for n, units in enumerate(data_out.Units_Sold):
if n == 0:
trend.append(0)
elif data_out.Units_Sold[i-1]>=units and data_out.product_number.loc[i] == data_out.product_number.loc[i-1]:
trend.append(0)
elif data_out.Num_Contrs[i-1]<units and data_out.product_number.loc[i] == data_out.product_number.loc[i-1]:
trend.append(0.08)
data_out.Trend = trend
Edit:
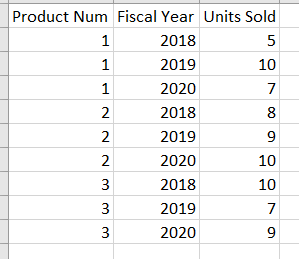
CodePudding user response:
How about using pct_change() and np.where()? Here's a toy example. Note that due to the shuffling, the pct change column is out of order at the end, but the trend change is correct. Just left it in for understanding logic. Also the index has been modified, so be aware of that and sort by idx as needed.
import numpy as np
import pandas as pd
df = pd.DataFrame({'Fiscal Year': {0: 2020, 1: 2019, 2: 2021, 3: 2020, 4: 2022},
'Product Num': {0: 'widget', 1: 'doodad', 2: "widget", 3: 'doodad', 4: 'widget'},
'Value': {0: 1000, 1: 1100, 2: 900, 3: 1300, 4: 800}})
# sort by year and prod so we can calc percent change
df=df.sort_values(by=['Fiscal Year', 'Product Num'])
df['pct_change'] = df['Value'].pct_change()
df['trend'] = np.where(df['pct_change'] > 0, ' ', '-')
# find the idx values of first year so we can overwrite them
first_year = df.groupby('Product Num').agg({'Fiscal Year':'idxmin'})
first_year_idxs = first_year['Fiscal Year'].tolist()
df['trend'] = np.where(df.index.isin(first_year_idxs), ' ', df['trend'])
Output df:
Fiscal Year Product Num Value pct_change trend
1 2019 doodad 1100 NaN
3 2020 doodad 1300 0.181818
0 2020 widget 1000 -0.230769
2 2021 widget 900 -0.100000 -
4 2022 widget 800 -0.111111 -