Background
- I am searching a 2D grid for a word.
- We can search left/right and up/down.
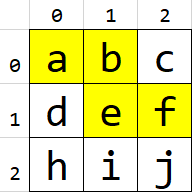
- For example, in this grid, searching for
"abef"starting at(0,0)will returnTrue
Example (grid1):
Where I'm at
- The recursive version gives expected results (see
dfs_rec()below). - The iterative version also gives expected results (see
dfs_iter()below). However, in this version I am making a copy of thevisitedset onto the stack at every node.
My question is
- Is there a way to avoid the copy (
visited.copy()) in the iterative version, and add/remove to a singlevisitedset as in the recursive version?
Further details and stuff I've tried...
In
dfs_rec()there is a singleset()namedvisited, and it's changed viavisited.add((row,col))andvisited.remove((row,col))But in
dfs_iter()I am pushingvisited.copy()onto the stack each time, to prevent nodes from being marked as visited incorrectly.I have seen some iterative examples where they use a single
visitedset, without making copies or removing anything from the set, but that does not give me the right output in these examples (seedfs_iter_nocopy()usinggrid3below).
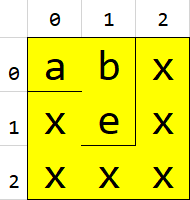
As an example, take this grid:

- Say you search for
"abexxxxxx"(covering the entire grid), the expected output will beTrue
But
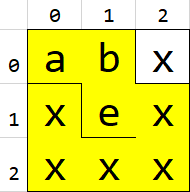
dfs_iter_nocopy()will give incorrect output on one ofgrid2orgrid3(they are just mirrored, one will pass and one will fail), depending on the order you push nodes onto the stack.What's happening is, when you search for
"abexxxxxx", it searches a path like this (only hitting 5 x's, while it needs 6).
- It marks the
xat(1,0)as visited, and when it's time to search that branch, it stops at(1,0), like this:
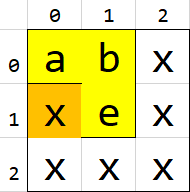
Code
def width (g): return len(g)
def height (g): return len(g[0])
def valid (g,r,c): return r>=0 and c>=0 and r<height(g) and c<width(g)
def dfs_rec (grid, word, row, col, visited):
if not valid(grid, row, col): return False # (row,col) off board
if (row,col) in visited: return False # already checked
if grid[row][col] != word[0]: return False # not right path
if grid[row][col] == word: # len(word)==1
return True
visited.add((row,col))
if dfs_rec(grid, word[1:], row, col 1, visited): return True
if dfs_rec(grid, word[1:], row 1, col, visited): return True
if dfs_rec(grid, word[1:], row, col-1, visited): return True
if dfs_rec(grid, word[1:], row-1, col, visited): return True
# Not found on this path, don't block for other paths
visited.remove((row,col))
return False
def dfs_iter (grid, start_word, start_row, start_col, start_visited):
stack = [ (start_row, start_col, start_word, start_visited) ]
while len(stack) > 0:
row,col,word,visited = stack.pop()
if not valid(grid, row, col): continue
if (row,col) in visited: continue
if grid[row][col] != word[0]: continue
if grid[row][col] == word:
return True
visited.add((row,col))
stack.append( (row, col 1, word[1:], visited.copy()) )
stack.append( (row 1, col, word[1:], visited.copy()) )
stack.append( (row, col-1, word[1:], visited.copy()) )
stack.append( (row-1, col, word[1:], visited.copy()) )
return False
def dfs_iter_nocopy (grid, start_word, start_row, start_col):
visited = set()
stack = [ (start_row, start_col, start_word) ]
while len(stack) > 0:
row,col,word = stack.pop()
if not valid(grid, row, col): continue
if (row,col) in visited: continue
if grid[row][col] != word[0]: continue
if grid[row][col] == word:
return True
visited.add((row,col))
stack.append( (row, col 1, word[1:]) )
stack.append( (row 1, col, word[1:]) )
stack.append( (row, col-1, word[1:]) )
stack.append( (row-1, col, word[1:]) )
return False
if __name__ == '__main__':
grid = [ 'abc', 'def', 'hij' ]
grid2 = [ 'abx', 'xex', 'xxx' ]
grid3 = [ 'xba', 'xex', 'xxx' ]
print( dfs_rec(grid, 'abef', 0, 0, set() ) == True )
print( dfs_rec(grid, 'abcd', 0, 0, set() ) == False )
print( dfs_rec(grid, 'abcfjihde', 0, 0, set() ) == True )
print( dfs_rec(grid, 'abefjihd', 0, 0, set() ) == True )
print( dfs_rec(grid, 'abefjihda', 0, 0, set() ) == False )
print( dfs_rec(grid, 'abefjihi', 0, 0, set() ) == False )
print( dfs_iter(grid, 'abc', 0, 0, set() ) == True )
print( dfs_iter(grid, 'abef', 0, 0, set() ) == True )
print( dfs_iter(grid, 'abcd', 0, 0, set() ) == False )
print( dfs_iter(grid, 'abcfjihde', 0, 0, set() ) == True )
print( dfs_iter(grid, 'abefjihd', 0, 0, set() ) == True )
print( dfs_iter(grid, 'abefjihda', 0, 0, set() ) == False )
print( dfs_iter(grid, 'abefjihi', 0, 0, set() ) == False )
print( dfs_rec(grid2, 'abexxxxxx', 0, 0, set() ) == True )
print( dfs_iter(grid2, 'abexxxxxx', 0, 0, set() ) == True )
print( dfs_iter_nocopy(grid2, 'abexxxxxx', 0, 0 ) == True )
print( dfs_rec(grid3, 'abexxxxxx', 0, 2, set() ) == True )
print( dfs_iter(grid3, 'abexxxxxx', 0, 2, set() ) == True )
print( dfs_iter_nocopy(grid3, 'abexxxxxx', 0, 2 ) == True ) # <-- Problem, prints False
CodePudding user response:
You noticed that the recursive version was able to use a single visited accumulator by resetting it with visited.remove((row,col)) when backtracking. So the same can be done here by imitating the function call stack so that we know when backtracking occurs.
def dfs_iter_nocopy (grid, start_word, start_row, start_col):
visited = [] # order now matters
last_depth = 0 # decreases when backtracking
stack = [ (start_row, start_col, start_word, last_depth 1) ]
while len(stack) > 0:
row, col, word, depth = stack.pop()
if not valid(grid, row, col): continue
while last_depth >= depth: # just backtracked
last_depth -= 1
visited.pop() # simulate returning from the call stack
if (row,col) in visited: continue
if grid[row][col] != word[0]: continue
if grid[row][col] == word:
return True
visited.append((row,col))
last_depth = depth
depth = 1 # simulate adding recursive call to the call stack
stack.append( (row, col 1, word[1:], depth) )
stack.append( (row 1, col, word[1:], depth) )
stack.append( (row, col-1, word[1:], depth) )
stack.append( (row-1, col, word[1:], depth) )
return False
The depth will increase as a new tile is explored, but decrease as we exhaust the possibilities for a particular path and revert to an earlier fork. This is what I mean by backtracking.
edit: variable name