Say I have the following dataframe:
import pandas as pd
df = pd.DataFrame(columns=['Time', 'Event'])
df.Time = ['06:15.2', '06:15.2', '06:45.3', '43:26.8', '43:26.8', '43:57.9', '27:30.0', '27:31.1', '27:31.1', '27:31.1', '27:31.1', '32:41.0', '10:22.6', '10:22.6', '10:54.7', '11:30.3', '11:30.3']
df.Event = ['login', 'other', 'logout', 'login', 'other', 'logout', 'login', 'other', 'other', 'login', 'logout', 'logout', 'login', 'other', 'logout', 'login', 'other']
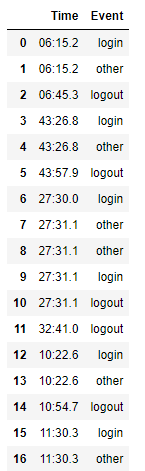
I want to find the time difference between a login and the logout that comes immediately after the login. That is, if there are multiple logins and then one logout, I want to find the time difference between the last login and the logout.
My attempt to do this is as follows:
import numpy as np
import datetime
diff = np.zeros(len(df))
for i in range(len(df)):
if df.Event[i]=='login':
for j in range(len(df[i:])):
if df.Event[j]=='logout':
diff[j] = (datetime.datetime.strptime(df.Time[j], '%M:%S.%f') - datetime.datetime.strptime(df.Time[i], '%M:%S.%f'))/ datetime.timedelta(milliseconds=1)
df['Diff'] = diff
df
But it doesn't produce the right result:
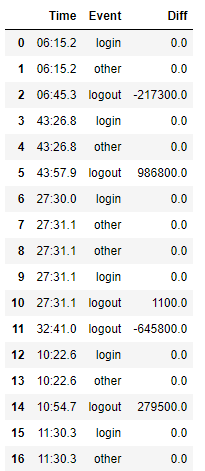
The correct result should be: the non-zero numbers in the Diff column should be 30.1, 31.1, 0.0, 0.0 (not sure how to handle this case, as this logout comes after a logout...considering pairwise logins and logouts would be adding another level of complexity), 32.1
Is there any Pythonic way of doing this?
CodePudding user response:
I've got some very long and inefficient code, but it works. The first function is used later to turn times into the string format you want. The Times and Events columns are turned into lists and then list comprehension is done to turn the time strings into minutes.
# str is in HH:MM:SS.MS format. this_time is in minutes.
def convert_time_to_str(this_time):
seconds = (this_time % 1)*60
ms = int(round((seconds % 1) * 1000, 0))
seconds = int(seconds // 1)
if this_time < 1:
return str(seconds) "." str(ms)
minutes = this_time % 1
hours = int(minutes // 60)
minutes = int(minutes - hours*60)
if minutes < 60:
return str(minutes) ":" str(seconds) "." str(ms)
else:
return str(hours) ":" str(minutes) ":" str(seconds) "." str(ms)
times_list = df["Time"].tolist()
events = df["Event"].tolist()
times = []
# turning times_list into numbers (in terms of minutes).
for i in range(len(times_list)):
this_time_str = times_list[i]
this_time_split = this_time_str.split(":")
s, ms = this_time_split[-1].split(".")
if len(this_time_split) == 2:
h = 0
m = int(this_time_split[0])
else:
h = int(this_time_split[0])
m = int(this_time_split[1])
# times are in terms of minutes, since that seems to be the relevant scale in your case.
this_time = int(h)*60 int(m) int(s)/60 int(ms)/(60*1000)
times.append(this_time)
# Finding time differences between login and logout.
final_time_diffs = [0]*len(events)
for i in range(1, len(events)):
# iterate through rows corresponding to a logout.
if events[i] == "logout":
# j is how many indices before i (the logout row) the closest login is.
last_login_idx = ""
j = 1
found_login = False
while last_login_idx == "" and j <= i:
previous_event = events[i-j]
# If previous event was a logout, ignore this entire logout row.
if previous_event == "logout":
break
elif previous_event == "login":
last_login_idx = i - j
found_login = True
break
j = 1
# Find the time_diff between logout and closest previous login.
if found_login:
this_time_diff = times[i] - times[last_login_idx]
this_time_diff_str = convert_time_to_str(this_time_diff)
final_time_diffs[i] = this_time_diff_str
else:
final_time_diffs[i] = 0
# Name this column whatever you want; main thing is that it'll contain the time differences between login and logout. If there are 2 logouts in a row, the 2nd logout will have time_diff 0.
df["TimeDiffs"] = final_time_diffs
I haven't tested whether the code can put up with hours values in the Times column, but theoretically, it should. It cannot deal with times rolling over to the next day, so be aware! Also, if the hour values are very large, this code will unnecessarily eat up memory just to store the large times, since times are in terms of minutes; in that case, I'd advise working in chunks and subtracting a certain number of hours from all the times in question.
CodePudding user response:
import pandas as pd
df = pd.DataFrame(columns=['Time', 'Event'])
df.Time = ['06:15.2', '06:15.2', '06:45.3', '43:26.8', '43:26.8', '43:57.9', '27:30.0', '27:31.1', '27:31.1', '27:31.1', '27:31.1', '32:41.0', '10:22.6', '10:22.6', '10:54.7', '11:30.3', '11:30.3']
df.Event = ['login', 'other', 'logout', 'login', 'other', 'logout', 'login', 'other', 'other', 'login', 'logout', 'logout', 'login', 'other', 'logout', 'login', 'other']
df["Time"] = df["Time"].apply(lambda x : int(x[0:2])*60 float(x[3:]))
df["Time1"] = df["Time"].shift(1).fillna(0)
df1 = df[df["Event"].isin(["logout","login"])]
df1["Event1"] = df1["Event"].shift(1).fillna(0)
df2 = df1[(df1["Event"] == "logout") & (df1["Event1"] == "login")].assign( Duration = df1["Time"] - df1["Time1"])
df.merge(df2, how = "left").drop(["Time1","Event1"], axis = 1).fillna(0)
Here is the output :
Out[53]:
Time Event Duration
0 375.2 login 0.0
1 375.2 other 0.0
2 405.3 logout 30.1
3 2606.8 login 0.0
4 2606.8 other 0.0
5 2637.9 logout 31.1
6 1650.0 login 0.0
7 1651.1 other 0.0
8 1651.1 other 0.0
9 1651.1 login 0.0
10 1651.1 logout 0.0
11 1961.0 logout 0.0
12 622.6 login 0.0
13 622.6 other 0.0
14 654.7 logout 32.1
15 690.3 login 0.0
16 690.3 other 0.0