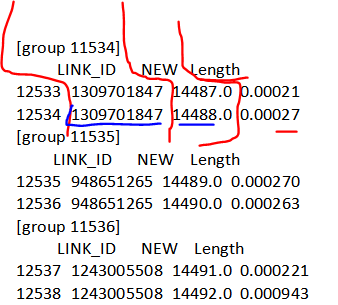
I have three separate columns: Link_Id, NEW, Length in a data frame.
I want to group similar Link_Ids together and then collect their Length values, out of those having the maximum Length value I want to return their (Link_Id) and (NEW) column values.
import pandas as pd
# List all columns you want to include in the dataframe. I include all with:
cols = ['LINK_ID', 'NEW', 'Length'] # Or list them manually: ['kommunnamn', 'kkod', ... ]
# A generator to yield one row at a time
datagen = ([f[col] for col in cols] for f in vlayer.getFeatures())
df = pd.DataFrame.from_records(data=datagen, columns=cols)
dff = df.groupby((df['LINK_ID'].shift() != df['LINK_ID']).cumsum())
for k, v in dff:
print(f'[group {k}]')
print(v)
result = df.groupby('LINK_ID').agg({'Length': ['max']})
CodePudding user response:
IIUC, try:
result = df.loc[df.groupby("LINK_ID")["Length"].idxmax()]