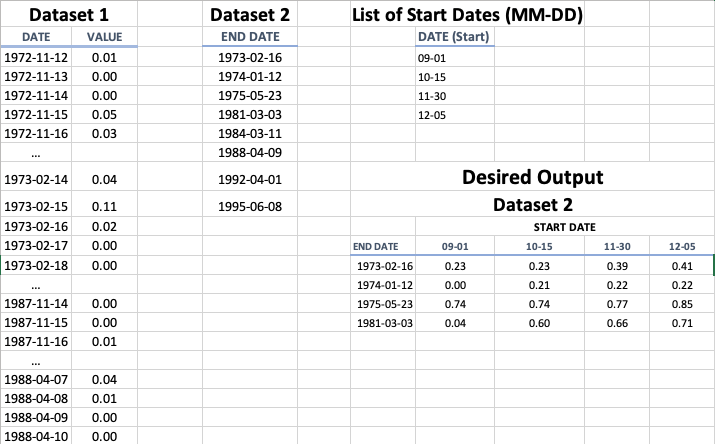
I have two datasets. One contains 63 years of environmental data with values for each date (~23K dates), the second contains a list dates (~1K) when environmental samples were collected. I need to sum values from the first set with the end date from the second set. The scripting problem is that the start date will be passed as a list of MMs-DDs and the year will always be in the year previous to the end date. For example, if the end dates are 1973-02-16 and 1988-04-09 and the start date is Nov 15, then the appropriate start date year for each end date would be 1972-11-15 and 1987-11-15.
Therefore, how do I iterate through the list of end dates, for each end date year subtract one year, add that year to the start date, so that I can then sum the values between start and end dates (where I will then store the value in a column next to the end date)? The Python sticking point for me is how to get the start date in YYYY-MM-DD format so that I can sum the values between the two dates. Below are datasets created for illustrative purposes. Thanks in advanced for suggestions--I learn a lot of Python from reading answers to real world problems on this forum.
CodePudding user response:
Building the sample datasets
import pandas as pd
import numpy as np
import datetime
dat_r = pd.date_range('1972-11-12', '1988-04-10')
dataset_1 = pd.DataFrame({'DATE': dat_r, 'VALUE':np.random.rand(dat_r.__len__())})
dataset_2 = pd.DataFrame({'END DATE': [datetime.date(1973,2,16), datetime.date(1974,1,12), datetime.date(1975,5,23), datetime.date(1981,3,3)]})
list_of_start_dates = pd.DataFrame({'DATE (Start)': ['09-01', '10-15', '11-30', '12-05']})
You can build the desired dataset as follows:
dff = pd.DataFrame(index=dataset_2['END DATE'], columns=list_of_start_dates['DATE (Start)'])
dff = dff.melt(ignore_index=False)
The year can be added to the date, like this
dff['AUX'] = pd.to_datetime(dff.index.map(lambda x: str(x.year-1)) "-" dff['DATE (Start)'])