I'm trying to plot data using the Seaborn library where:
x-axis - movie release year
y-axis - movie rating (0-10, discrete)
I'm using a scatterplot at the moment. My data is in a Pandas dataframe.
Obviously because the rating data I have is discrete integers, a lot of them stack on top of each other. How can I make the size of each dot scale with the frequency of appearance in the dataset?
For instance, if the number of 6/10 ratings in 2008 is higher than any other rating/year combination, I want that dot size (or something else in the plot) to indicate this.
Is there a different plot I should use for something like this instead?
CodePudding user response:
Is there a different plot I should use for something like this instead?
I suggest visualizing this as a 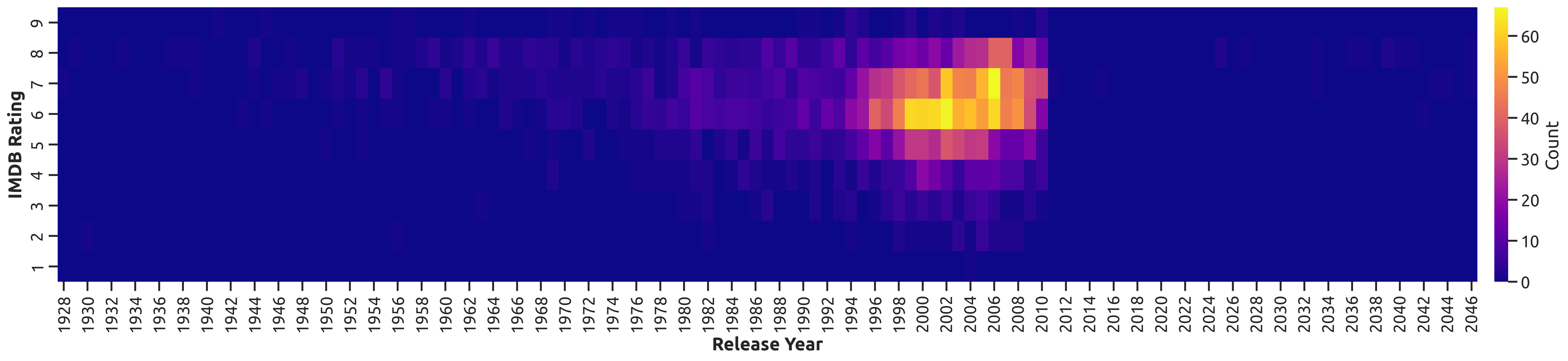
But if you still prefer a 
Data for reference:
url = 'https://raw.githubusercontent.com/vega/vega/main/docs/data/movies.json'
df = pd.read_json(url)[['Title', 'Release Date', 'IMDB Rating']]
df['Release Year'] = pd.to_datetime(df['Release Date']).dt.year
df['IMDB Rating'] = df['IMDB Rating'].round().astype('Int8')