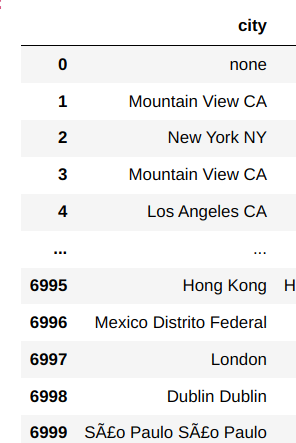
I have a dataframe column with city locations and some of the cells have the same value (city) twice within each cell. I was wondering how to get rid of one of the values. eg. Instead of it saying Dublin Dublin below it will only say Dublin once.
I have tried df['city'].apply(set) but it doesn't give me what I am looking for.
Any advice much appreciated. Please see the image below:
CodePudding user response:
You can split each item by (space) and convert each list of split strings to a set (which is deduplicated, but not sorted), and then re-join:
df['city'] = df['city'].str.split().apply(lambda x: pd.Series(x).drop_duplicates().tolist()).str.join(' ')
Output:
>>> df
city
0 Los Angeles CA
1 none
2 London
3 Dublin