The first few lines of my input csv file ("genus_counts.csv") look like below
Sample,Woeseia,Candidatus_Nitrosopumilus,Nitrospira,Nitrospina,Pseudahrensia,AqS1,Salinicola,Pir4_lineage,Subgroup_10,BD1-7_clade,Sva0996_marine_group,Anoxybacillus,Others,Unclassified
BW1,1.73959,0.474433,0,1.15973,0,0,3.32103,0,0,0,0,8.69794,27.464423,57.1429
BW2,0.424628,0.679406,0,0,0,0,9.95754,0,0.191083,0,1.18896,0,35.7749522,51.7834
and I intend to make a stacked bar chart based on this. I tried the below R code but the names on the legend have still got underscores on them. I introduced the line pcm %>% rename_all(~gsub("_", " ", .)) so as to replace all underscores with spaces but nothing gets changed on the legend (the underscores remain on the plot!). Any help here would be appreciated.
library(ggplot2)
library(reshape2)
pc = read.csv("genus_counts.csv", header = TRUE)
pcm = melt(pc, id = c("Sample"))
pcm$Sample <- factor(pcm$Sample,levels=unique(pcm$Sample))
pcm %>% rename_all(~gsub("_", " ", .))
mx = ggplot(pcm, aes(x = Sample, fill = variable, y = value))
geom_bar(stat = "identity", colour = "black")
theme(axis.text.x = element_text(angle = 90, size = 14, colour = "black", vjust = 0.5, hjust = 1, face= "bold"),
axis.title.y = element_text(size = 16, face = "bold"), legend.title = element_text(size = 16, face = "bold"),
legend.text = element_text(size = 12, face = "bold", colour = "black"),
axis.text.y = element_text(colour = "black", size = 12, face = "bold"))
scale_y_continuous(expand = c(0,0))
labs(x = "", y = "Relative Abundance (%)", fill = "Taxon")
scale_fill_viridis_d(option="plasma")
mx
CodePudding user response:
rename_all is used to change the column names of the function. After you melt the dataframe the variables are no longer column names but values of variable column.
So either you can use rename_all before melt step or you can replace the values in a mutate statement after melting the dataframe.
library(dplyr)
library(ggplot2)
pcm %>%
mutate(variable = gsub("_", " ", variable)) %>%
ggplot(aes(x = Sample, fill = variable, y = value))
geom_bar(stat = "identity", colour = "black")
theme(axis.text.x = element_text(angle = 90, size = 14,
colour = "black", vjust = 0.5, hjust = 1, face= "bold"),
axis.title.y = element_text(size = 16, face = "bold"),
legend.title = element_text(size = 16, face = "bold"),
legend.text = element_text(size = 12, face = "bold", colour = "black"),
axis.text.y = element_text(colour = "black", size = 12, face = "bold"))
scale_y_continuous(expand = c(0,0))
labs(x = "", y = "Relative Abundance (%)", fill = "Taxon")
scale_fill_viridis_d(option="plasma")
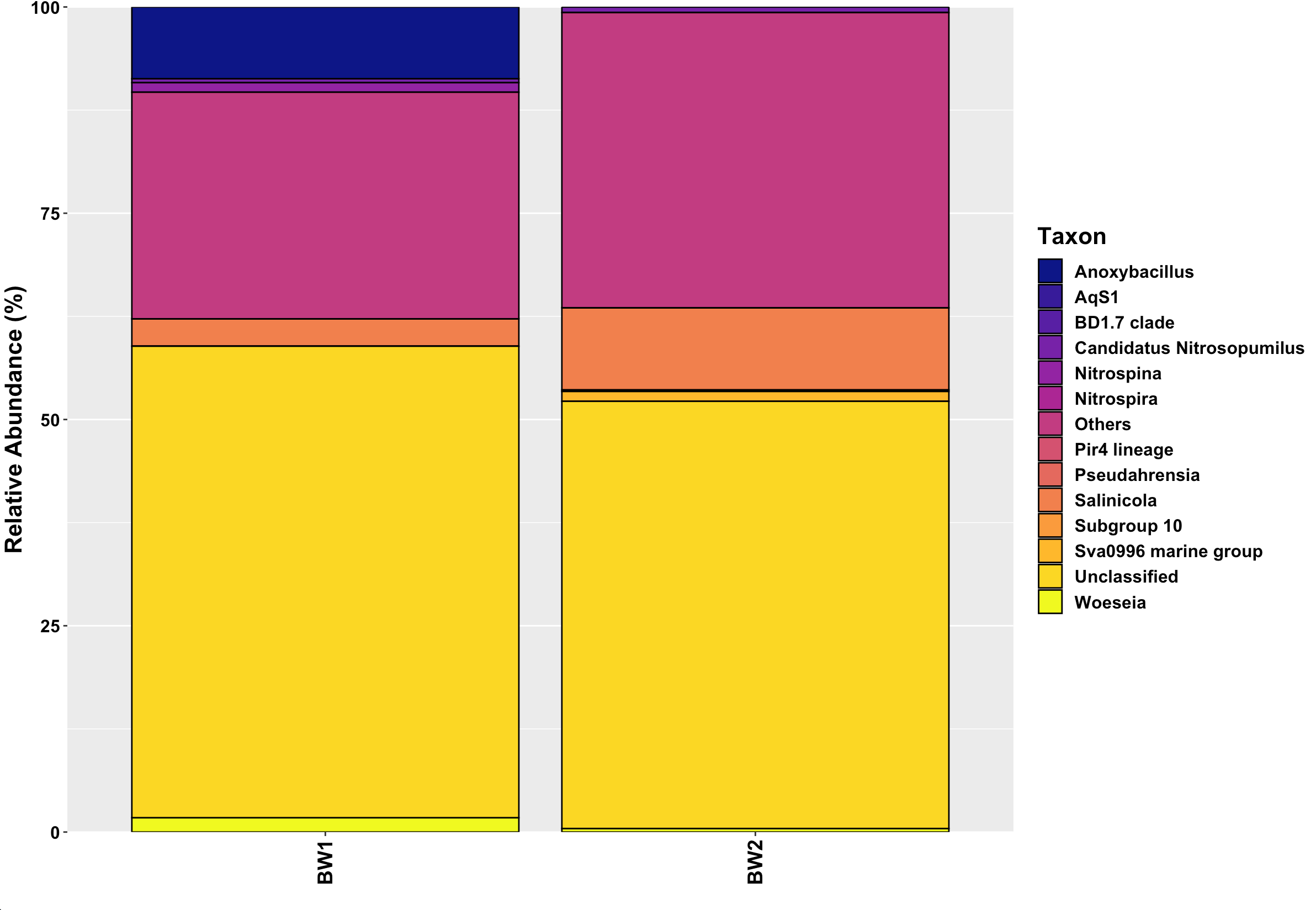
CodePudding user response:
A second option to achieve your desired result would be to pass a function to the labels argument of the scale which replaces the underscores with a space, i.e. labels = ~ gsub("_", " ", .x):
library(ggplot2)
library(reshape2)
pcm <- melt(pc, id = c("Sample"))
pcm$Sample <- factor(pcm$Sample, levels = unique(pcm$Sample))
ggplot(pcm, aes(x = Sample, fill = variable, y = value))
geom_bar(stat = "identity", colour = "black")
theme(
axis.text.x = element_text(angle = 90, size = 14, colour = "black", vjust = 0.5, hjust = 1, face = "bold"),
axis.title.y = element_text(size = 16, face = "bold"), legend.title = element_text(size = 16, face = "bold"),
legend.text = element_text(size = 12, face = "bold", colour = "black"),
axis.text.y = element_text(colour = "black", size = 12, face = "bold")
)
scale_y_continuous(expand = c(0, 0))
labs(x = "", y = "Relative Abundance (%)", fill = "Taxon")
scale_fill_viridis_d(option = "plasma", labels = ~ gsub("_", " ", .x))
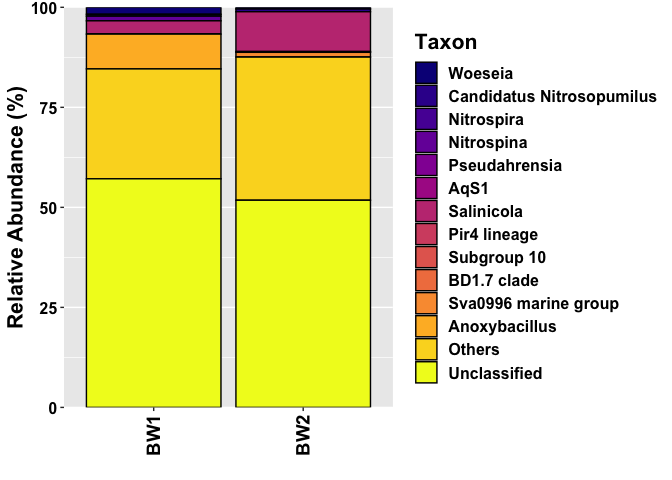
DATA
pc <- structure(list(
Sample = c("BW1", "BW2"), Woeseia = c(
1.73959,
0.424628
), Candidatus_Nitrosopumilus = c(0.474433, 0.679406),
Nitrospira = c(0L, 0L), Nitrospina = c(1.15973, 0), Pseudahrensia = c(
0L,
0L
), AqS1 = c(0L, 0L), Salinicola = c(3.32103, 9.95754),
Pir4_lineage = c(0L, 0L), Subgroup_10 = c(0, 0.191083), BD1.7_clade = c(
0L,
0L
), Sva0996_marine_group = c(0, 1.18896), Anoxybacillus = c(
8.69794,
0
), Others = c(27.464423, 35.7749522), Unclassified = c(
57.1429,
51.7834
)
), class = "data.frame", row.names = c(NA, -2L))