I've got a dataframe in pandas that stores the Id of a person, the quality of interaction, and the date of the interaction. A person can have multiple interactions across multiple dates, so to help visualise and plot this I converted it into a pivot table grouping first by Id then by date to analyse the pattern over time.
e.g.
import pandas as pd
df = pd.DataFrame({'Id':['A4G8','A4G8','A4G8','P9N3','P9N3','P9N3','P9N3','C7R5','L4U7'],
'Date':['2016-1-1','2016-1-15','2016-1-30','2017-2-12','2017-2-28','2017-3-10','2019-1-1','2018-6-1','2019-8-6'],
'Quality':[2,3,6,1,5,10,10,2,2]})
pt = df.pivot_table(values='Quality', index=['Id','Date'])
print(pt)
Leads to this:
| Id | Date | Quality |
|---|---|---|
| A4G8 | 2016-1-1 | 2 |
| 2016-1-15 | 4 | |
| 2016-1-30 | 6 | |
| P9N3 | 2017-2-12 | 1 |
| 2017-2-28 | 5 | |
| 2017-3-10 | 10 | |
| 2019-1-1 | 10 | |
| C7R5 | 2018-6-1 | 2 |
| L4U7 | 2019-8-6 | 2 |
However, I'd also like to...
- Measure the time from the first interaction for each interaction per Id
- Measure the time from the previous interaction with the same Id
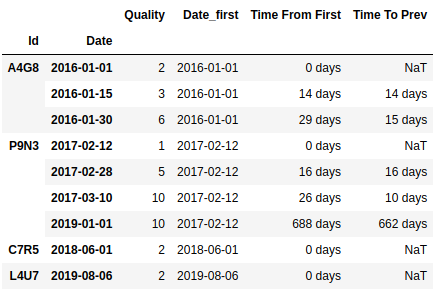
So I'd get a table similar to the one below
| Id | Date | Quality | Time From First | Time To Prev |
|---|---|---|---|---|
| A4G8 | 2016-1-1 | 2 | 0 days | NA days |
| 2016-1-15 | 4 | 14 days | 14 days | |
| 2016-1-30 | 6 | 29 days | 14 days | |
| P9N3 | 2017-2-12 | 1 | 0 days | NA days |
| 2017-2-28 | 5 | 15 days | 15 days | |
| 2017-3-10 | 10 | 24 days | 9 days |
The Id column is a string type, and I've converted the date column into datetime, and the Quality column into an integer.
The column is rather large (>10,000 unique ids) so for performance reasons I'm trying to avoid using for loops. I'm guessing the solution is somehow using pd.eval but I'm stuck as to how to apply it correctly.
Apologies I'm a python, pandas, & stack overflow) noob and I haven't found the answer anywhere yet so even some pointers on where to look would be great :-). Many thanks in advance
CodePudding user response:
Convert Dates to datetimes and then substract minimal datetimes per groups by