I am just trying to get some data and re-arrange it. Here is my dataset showing foods and the scores they received in different years. What I want to do is find the foods which had the lowest and highest scores on average and track their scores across the years.
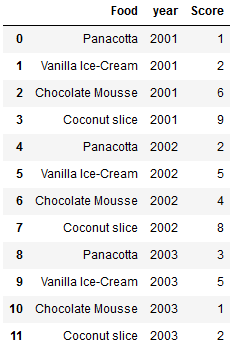
Here is my code so far:
#import
menu = pd.read_csv("Food.csv")
#Get average rank
avg_ranking = menu.groupby(['Food']).Score.mean().round()
#Convert to DataFrame
data2 = pd.DataFrame(avg_ranking.reset_index(name = "Group"))
#Display the highest and lowest ranking
filter_food = data2[['Food', 'Group']][(data2['Group'] == avg_ranking.max()) | (data2['Group'] == avg_ranking.min())]
#This is where I have been playing around with getting the individual min and max food names:
filter_food_max = data2[['Food']][(data2['Group'] == data2.Group.max())]
Max = filter_food_max.Food
filter_food_min = data2[['Food']][(data2['Group'] == data2.Group.min())]
Min = filter_food_min.Food
The next part is where I am a little stuck (please note - I do want to practice using the group-by, so it'll be super awesome if that is kept somewhere): I'd need to display the max and min foods from the original dataset that would show all the columns - Food, year, Score. This is what I have tried, but it doesn't work:
menu[menu.Food == Max & menu.Food == Min]
Basically I want it to display something like the below in a dataframe, so I can plot some graphs (i.e. I want to then make a line plot which would display the years on the x-axis, scores on the y-axis and plot the lowest scoring food and the top scoring food:
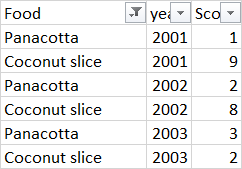
If you guys know any other ways of doing this (using the group-by function), please let me know!
Any help would be appreciated
CodePudding user response:
You can select first and last rows per year by Series.duplicated with invert mask and chain by | for bitwise OR, filter in boolean indexing:
df1 = df[~df['year'].duplicated() | ~df['year'].duplicated(keep='last')]
Solution with groupby:
df1 = df.groupby('year').agg(['first','last']).stack(1).droplevel(1).reset_index()
If need minimal and maximal per years:
df = df.sort_values(['year','food'])
df2 = df[~df['year'].duplicated() | ~df['year'].duplicated(keep='last')]
Solution with groupby:
df2 = df.loc[df.groupby('year')['Score'].agg(['idxmax','idxmin']).stack()]