I'm using a combination of str.join (let's call the column joined col_str) and groupby (Let's call the grouped col col_a) in order to summarize data row-wise.
col_str, may contain nan values. Unsurprisingly, and as seen in str.join 
To mitigate this, I tried to convert col_str to string (e.g. df['col_str'] = df['col_str'].astype(str) ). But then, empty values now literally have a string nan value, hence considered non empty.
Not only that str.join now includes nan strings, but also other calculations over the script, that rely on those nans, are ruined.
To address that, I thought about converting just the non-empty values as follows:
df['col_str'] = np.where(pd.isnull(df['col_str']), df['col_str'],
df['col_str'].astype(str))
But now str.join return empty values again :-(
So, I tried fillna('') and even dropna(). None provided me with the desired results.
You get the vicious cycle here, right?
astype(str) => nan strings in join and calculations ruined
Leaving as-is => join.str returns empty results.
Thanks for your assistance!
Edit:
Data is read from a csv. Sample:
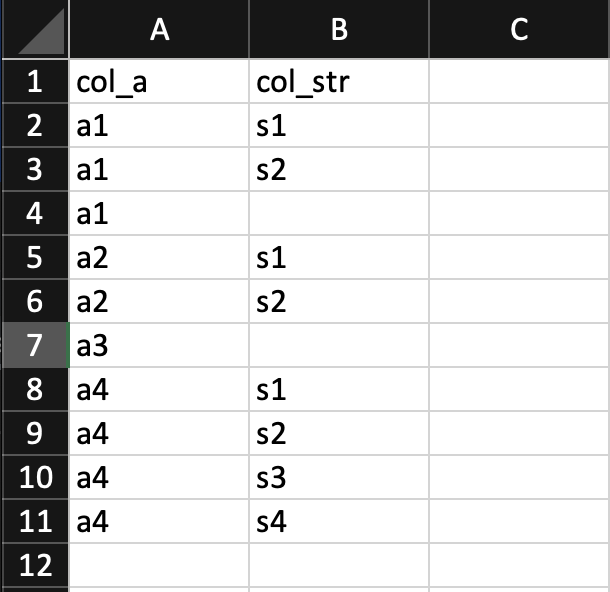
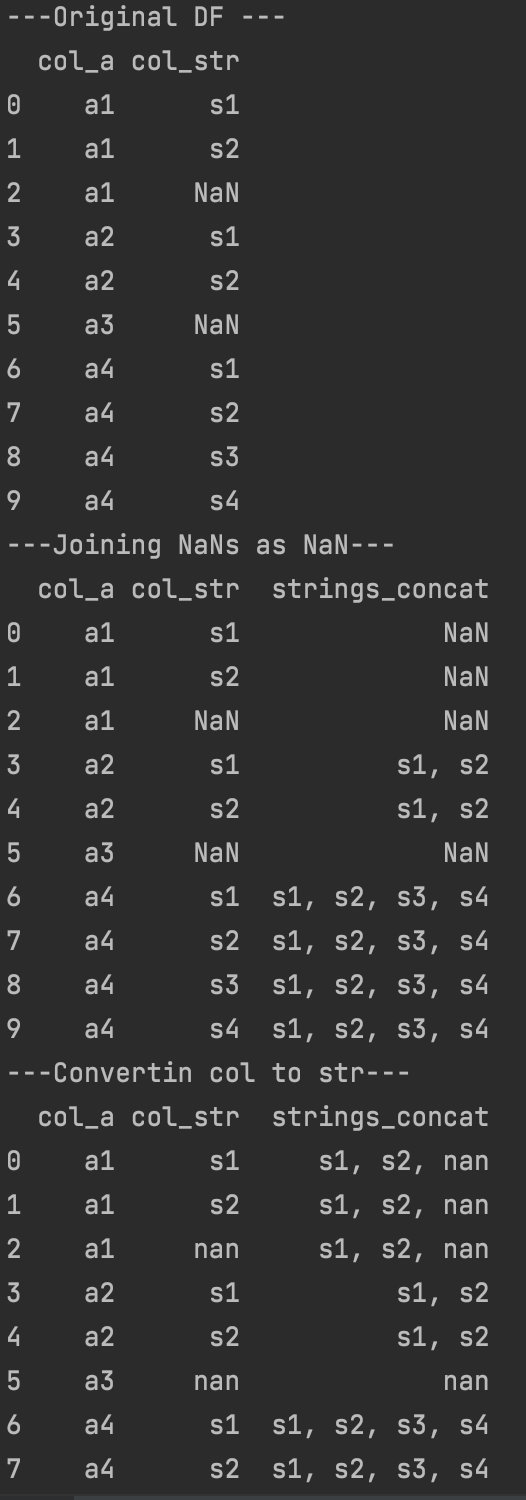
Code to test -
df = pd.read_csv('/Users/goidelg/Downloads/sample_data.csv', low_memory=False)
print("---Original DF ---")
print(df)
print("---Joining NaNs as NaN---")
print(df.join(df['col_a'].map(df.groupby('col_a')['col_str'].unique().str.join(', ')).rename('strings_concat')))
print("---Convertin col to str---")
df['col_str'] = df['col_str'].astype(str)
print(df.join(df['col_a'].map(df.groupby('col_a')['col_str'].unique().str.join(', ')).rename('strings_concat')))
And results for the script:
CodePudding user response:
First remove missing values by DataFrame.dropna or Series.notna in boolean indexing:
df = pd.DataFrame({'col_a':[1,2,3,4,1,2,3,4,1,2],
'col_str':['a','b','c','d',np.nan, np.nan, np.nan, np.nan,'a', 's']})
df1 = (df.join(df['col_a'].map(df[df['col_str'].notna()]
.groupby('col_a')['col_str'].unique()
.str.join(', ')). rename('labels')))
print (df1)
col_a col_str labels
0 1 a a
1 2 b b, s
2 3 c c
3 4 d d
4 1 NaN a
5 2 NaN b, s
6 3 NaN c
7 4 NaN d
8 1 a a
9 2 s b, s
df2 = (df.join(df['col_a'].map(df.dropna(subset=['col_str'])
.groupby('col_a')['col_str']
.unique().str.join(', ')).rename('labels')))
print (df2)
col_a col_str labels
0 1 a a
1 2 b b, s
2 3 c c
3 4 d d
4 1 NaN a
5 2 NaN b, s
6 3 NaN c
7 4 NaN d
8 1 a a
9 2 s b, s