I have about 1000s of files in a folder with single column data. I want to merge them as single file as filename as header and each file values in separte columns.
For example: File1.txt
-0.000633
-0.001362
-0.001909
-0.002638
-0.00282
-0.004096
File2.txt
-0.003002
-0.003184
-0.004096
-0.003913
File3.txt
-0.002638
-0.000086
0.001736
0.001736
0.001736
File4.txt
I want to merge all these files as follows:
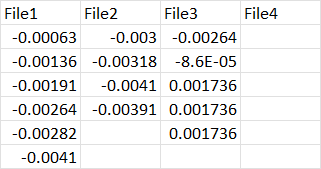
CodePudding user response:
file_list = ['File1.txt', 'File2.txt', 'File3.txt']
df = pd.DataFrame()
for file in file_list:
temp_df = pd.read_csv(file, header=None, names=[file[:-4]])
df = pd.concat([df, temp_df], axis=1)
print(df)
File1 File2 File3
0 -0.000633 -0.003002 -0.002638
1 -0.001362 -0.003184 -0.000086
2 -0.001909 -0.004096 0.001736
3 -0.002638 -0.003913 0.001736
4 -0.002820 NaN 0.001736
5 -0.004096 NaN NaN
CodePudding user response:
Using bash, and tabs separating columns:
#!/usr/bin/env bash
combine() {
local IFS=$'\t' f
local -a header
for f in "$@"; do
header =("$(basename "$f" .txt)")
done
printf "%s\n" "${header[*]}"
paste "$@"
}
combine File1.txt File2.txt File3.txt File4.txt > filename
Massaging the filenames into the header line is the tricky bit, paste is an easy way to merge the file contents.
CodePudding user response:
import pandas as pd
file_list = ["File1.txt", "File2.txt"]
pd.concat([pd.read_csv(f, names=[f.replace('.txt', '')]) for f in file_list], axis=1)