I have data like this:
df<-structure(list(fname = c("Linda", "Bob"), employee_number = c("00000123456",
"654321"), job_role = c("Dept Research Admin", "Research Regulatory Assistant"
), ActiveAccount = c("Yes", "Yes"), CanAccess = c("No", "No"),
oncore_roles___1 = c(1, 0), oncore_roles___2 = c(1, 0), oncore_roles___3 = c(1,
0), oncore_roles___4 = c(0, 0), oncore_roles___5 = c(0, 1
), oncore_roles___6 = c(0, 0), oncore_roles___7 = c(0, 1),
oncore_roles___8 = c(0, 0), oncore_roles___9 = c(0, 0), oncore_roles___10 = c(0,
0), oncore_roles___11 = c(0, 0), oncore_roles___12 = c(0,
1), oncore_roles___13 = c(0, 0), oncore_roles___14 = c(0,
0), oncore_roles___15 = c(0, 0), oncore_roles___16 = c(0,
0), oncore_roles___17 = c(0, 0)), row.names = c(NA, -2L), class = c("tbl_df",
"tbl", "data.frame"))
The columns that start with "oncore roles" all came from this multiple choice survey option:
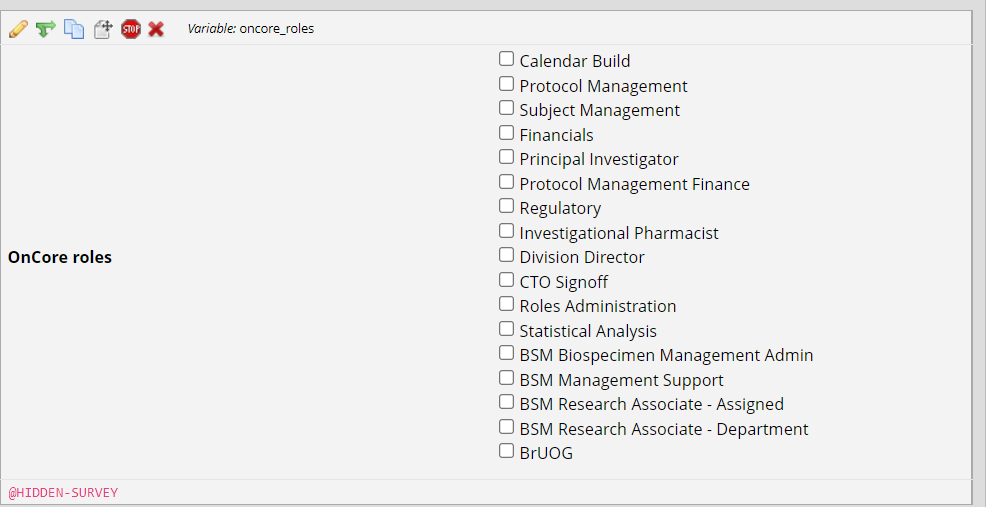
Where oncore_roles_1 stands for "calendar build", oncore_roles_5 stands for "principal investigator", etc... I.e. if Bob has a "1" marked in Oncore_roles_5, he was a principal investigator, if he had a zero in every other "oncore_roles" column... he was not those things.
I need to pivot my data so that it is longer and there's only one column for "Oncore Roles" which would have text that said what roles that person had, with a line for each role. So if Bob had three roles, he would get three nearly identical lines. Everything would be identical except the oncore_roles variable.
I know that's probably some version of pivot_longer but the trick (why I ask) is that I need to drop all the zero's. I.e. for this particular data, I'd be left with this:
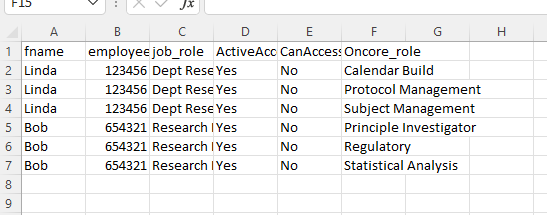
Thank you!
CodePudding user response:
Here is one option where we create a key/value dataset based on the multiple choice question and the column names, then do a join with the reshaped data to return the mapped column
library(dplyr)
library(tidyr)
library(stringr)
keydat <- tibble(name = str_c("oncore_roles___", 1:12),
Oncore_role = c("Calendar Build", "Protocol Management",
"Subject Managment", "Financials", "Principal Investigator",
"Protocol Management Finance", "Regulatory",
"Investigational Pharmacist", "Division Director", "CTO Signoff",
"Roles Administration", "Statistical Analysis"))
df %>%
pivot_longer(cols = starts_with('oncore_roles')) %>%
filter(value == 1) %>%
inner_join(keydat) %>%
select(-name)
-output
# A tibble: 6 × 7
fname employee_number job_role ActiveAccount CanAccess value Oncore_role
<chr> <chr> <chr> <chr> <chr> <dbl> <chr>
1 Linda 00000123456 Dept Research Admin Yes No 1 Calendar Build
2 Linda 00000123456 Dept Research Admin Yes No 1 Protocol Management
3 Linda 00000123456 Dept Research Admin Yes No 1 Subject Managment
4 Bob 654321 Research Regulatory Assistant Yes No 1 Principal Investigator
5 Bob 654321 Research Regulatory Assistant Yes No 1 Regulatory
6 Bob 654321 Research Regulatory Assistant Yes No 1 Statistical Analysis
CodePudding user response:
If you build a small lookup table of oncore roles, say roles, you can do the following:
df %>%
pivot_longer(cols = -(fname:CanAccess),names_prefix = "oncore_roles___",names_to = "id") %>%
filter(value==1) %>%
mutate(id=as.numeric(id)) %>%
left_join(roles, by="id") %>%
select(-(id:value))
Output (Note that my roles only has the first 5 roles, but you can make it longer, and then you could use an inner_join(), rather than left_join():
fname employee_number job_role ActiveAccount CanAccess Oncore_role
<chr> <chr> <chr> <chr> <chr> <chr>
1 Linda 00000123456 Dept Research Admin Yes No Calendar Build
2 Linda 00000123456 Dept Research Admin Yes No Protocol Management
3 Linda 00000123456 Dept Research Admin Yes No Subject Management
4 Bob 654321 Research Regulatory Assistant Yes No Principal Investigator
5 Bob 654321 Research Regulatory Assistant Yes No NA
6 Bob 654321 Research Regulatory Assistant Yes No NA
roles:
roles =tibble(
id = 1:5,
Oncore_role = c(
"Calendar Build",
"Protocol Management",
"Subject Management",
"Financial",
"Principal Investigator"
))