I want to plot the distribution of features in my dataset, So I go like this:
import pandas as pd
import numpy as np
x = ['P'] * 250 ['Q'] * 350 ['R'] * 200
y = np.random.randn(800)
df = pd.DataFrame({'Code':x, 'Value':y})
df['Value'].hist(by=df['Code'])
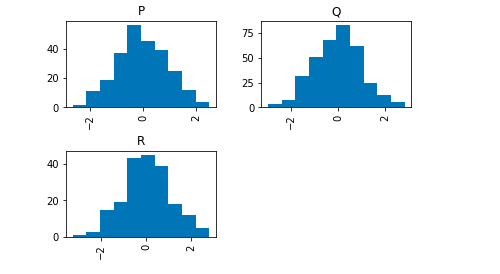
Output:
But I would like to impose the same scaling on axes in both feature plots, so it is easy to compare.
CodePudding user response:
As stated in the docs, use sharey=True:
sharey : bool, default False
In case subplots=True, share y axis and set some y axis labels to invisible.