I have date-interval-data with a "periodicity"-column representing how frequent the date interval occurs:
- Weekly: same weekdays every week
- Biweekly: same weekdays every other week
- Monthly: Same DATES every month
Moreover I have a "recurring_until"-column specifying when the recurrence should stop. What I need to accomplish is:
- creating a separate row for each recurring record until the "recurring_until" has been reached.
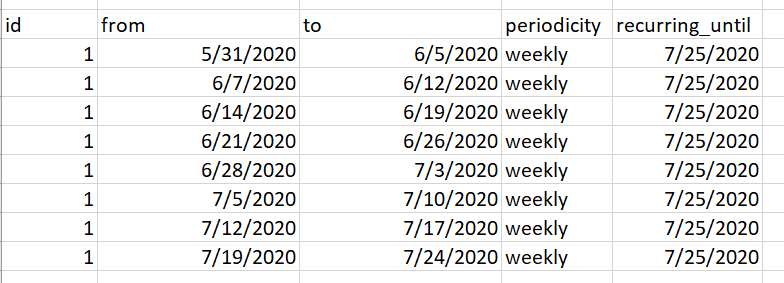
What I have:

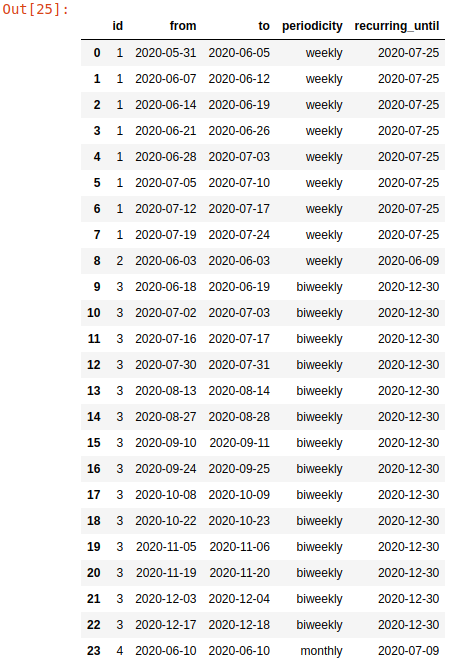
What I need:
I have been trying with various for loops without much success. Here is the sample data:
import pandas as pd
data = {'id':['1','2','3','4'],'from':['5/31/2020','6/3/2020','6/18/2020','6/10/2020'],'to':['6/5/2020','6/3/2020','6/19/2020','6/10/2020'],'periodicity':['weekly','weekly','biweekly','monthly'],'recurring_until':['7/25/2020','6/9/2020','12/30/2020','7/9/2020']}
df = pd.DataFrame(data)
CodePudding user response:
First of all preprocess:
df.set_index("id", inplace=True)
df["from"], df["to"], df["recurring_until"] = pd.to_datetime(df["from"]), pd.to_datetime(df.to), pd.to_datetime(df.recurring_until)
Next compute all the periodic from:
new_from = df.apply(lambda x: pd.date_range(x["from"], x.recurring_until), axis=1) #generate all days between from and recurring_until
new_from[df.periodicity=="weekly"] = new_from[df.periodicity=="weekly"].apply(lambda x:x[::7]) #slicing by week
new_from[df.periodicity=="biweekly"] = new_from[df.periodicity=="biweekly"].apply(lambda x:x[::14]) #slicing by biweek
new_from[df.periodicity=="monthly"] = new_from[df.periodicity=="monthly"].apply(lambda x:x[x.day==x.day[0]]) #selectiong only days equal to the first day
new_from = new_from.explode() #explode to obtain a series
new_from.name = "from" #naming the series
after this we have new_from like this:
id
1 2020-05-31
1 2020-06-07
1 2020-06-14
1 2020-06-21
1 2020-06-28
1 2020-07-05
1 2020-07-12
1 2020-07-19
2 2020-06-03
3 2020-06-18
3 2020-07-02
3 2020-07-16
3 2020-07-30
3 2020-08-13
3 2020-08-27
3 2020-09-10
3 2020-09-24
3 2020-10-08
3 2020-10-22
3 2020-11-05
3 2020-11-19
3 2020-12-03
3 2020-12-17
4 2020-06-10
Name: from, dtype: datetime64[ns]
Now lets compute all the periodic to as:
new_to = new_from (df.to-df["from"]).loc[new_from.index]
new_to.name = "to"
and we have new_to like this:
id
1 2020-06-05
1 2020-06-12
1 2020-06-19
1 2020-06-26
1 2020-07-03
1 2020-07-10
1 2020-07-17
1 2020-07-24
2 2020-06-03
3 2020-06-19
3 2020-07-03
3 2020-07-17
3 2020-07-31
3 2020-08-14
3 2020-08-28
3 2020-09-11
3 2020-09-25
3 2020-10-09
3 2020-10-23
3 2020-11-06
3 2020-11-20
3 2020-12-04
3 2020-12-18
4 2020-06-10
Name: to, dtype: datetime64[ns]
We can finally concatenate this two series and join them to the initial dataframe:
periodic_df = pd.concat([new_from, new_to], axis=1).join(df[["periodicity", "recurring_until"]]).reset_index()
result: