I'm having trouble understanding the Roslyn documentation and fiting it with what I see when working on an Incremental Source Generator.
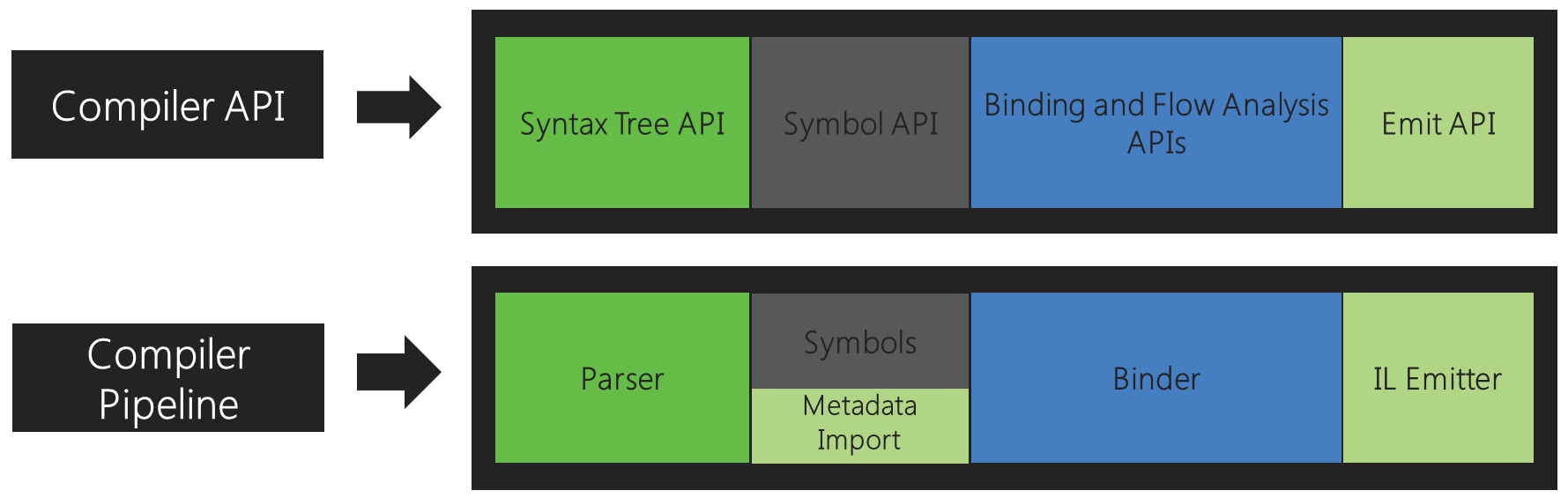
As i understand it the Syntax Tree is the result of Parser's work (is that correct?). I have access to the syntax tree through IncrementalGeneratorInitializationContext.SyntaxProvider. What trips me up is that the GeneratorSyntaxContext has a property called SemanticModel which seems to allow access to the symbols. I thought symbols were the product of a compilation which should not be available when dealing with syntax.
This leads me to another question. Which part of the Compiler Pipeline corresponds to the compilation? Is it the Binder?
CodePudding user response:
There's not a direct correlation for an incremental generator and the pipeline. Honestly that diagram should really be phrased more as:
- The parser produces SyntaxTree objects. (That's the dark green box.)
- Multiple SyntaxTree objects can be stuck together to make a Compilation object which gives access for symbols (gray box.)
- Given a Compilation and SyntaxTree, you can get a SemanticModel to ask further questions there (light green box).
- Compilation has an emit API you can use (that's the light green box.)
Think of it less as a pipeline and more the data structures as things point to other things, and you're stating in your generator what data structures you rely on. The idea is the more precise you can be, it lets us be faster in the IDE so we can rerun less the next time a keystroke happens.
In the IDE what's actually happening is a keystroke happens, we produce a new syntax tree for the file you edited, but we have all the existing trees that you didn't change. We produce a new compilation, and may rerun generators. We'll first run the "predicate" portion of the incremental syntax provider to find the nodes in the edited tree, but we still know the nodes from the prior run of your generator for the other trees. That way you're not having to reanalyze the parts that didn't change. We then give you an opportunity to look at the nodes a second time with semantics, which is more expensive.
The real goal with this is "walk through every syntax tree and find all the nodes that look like a specific pattern" is expensive, so this lets us stick caching in the middle to make that cheaper from one run to the next.