I am trying to remove all the characters from string in the DataFrame column but keep the comma but it still removes everything including the comma.
I know the question has been asked before but I tried many answers and all remove the comma as well.
df[new_text_field_name] = df[new_text_field_name].apply(lambda elem: re.sub(r"(@[A-Za-z0-9] )|([^0-9A-Za-z \t])|(\w :\/\/\S )|^rt|http. ?", "", str(elem)))
sample text:
'100 % polyester, Paperboard (min. 30% recycled), 100% polypropylene',
the required output:
' polyester, Paperboard , polypropylene',
CodePudding user response:
Possible solution is the following:
import pandas as pd
pd.set_option('display.max_colwidth', 200)
# set test data and create dataframe
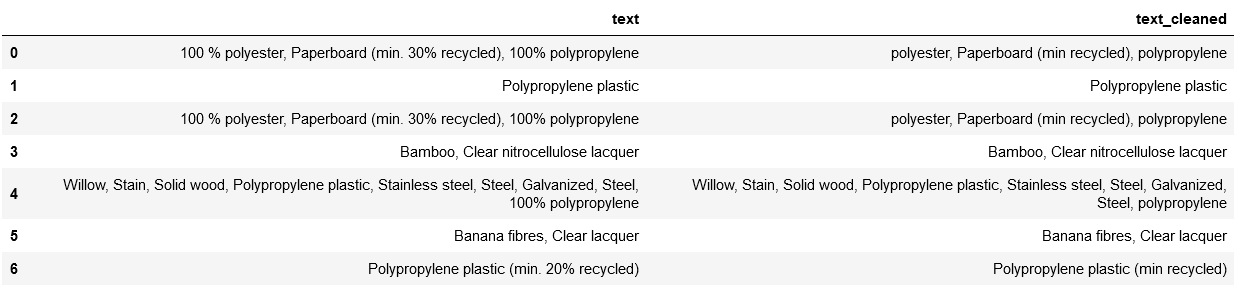
data = {"text": ['100 % polyester, Paperboard (min. 30% recycled), 100% polypropylene','Polypropylene plastic', '100 % polyester, Paperboard (min. 30% recycled), 100% polypropylene', 'Bamboo, Clear nitrocellulose lacquer', 'Willow, Stain, Solid wood, Polypropylene plastic, Stainless steel, Steel, Galvanized, Steel, 100% polypropylene', 'Banana fibres, Clear lacquer', 'Polypropylene plastic (min. 20% recycled)']}
df = pd.DataFrame(data)
def cleanup(txt):
re_pattern = re.compile(r"[^a-z, ()]", re.I)
return re.sub(re_pattern, "", txt).replace(" ", " ").strip()
df['text_cleaned'] = df['text'].apply(cleanup)
df
Returns
CodePudding user response:
Character.isDigit() and Character.isLetter() functions can be used to identify whether it is number or character.