Id Freq ID2 PSC
a1 0 xy 33
a1 0 yz 35
a1 1 xz 60
a2 0 pq 70
a2 1 qr 75
a2 0 rs 80
output should be
Id Freq ID2 PSC
a1 0 xy 33
yz 35
a1 1 xz 60
a2 0 pq 70
rs 80
a2 1 qr 75
after that check a1 and freq=o psc shlould be unique
CodePudding user response:
What exactly do you want to do?
If you want to mask the duplicated values with empty string (or NA) to highlight the consecutive duplicates like it would appear on a MultiIndex you could use:
df = df.sort_values(by=['Id', 'Freq'])
m = df.duplicated(['Id', 'Freq'])
df.loc[m, ['Id', 'Freq']] = ''
output:
Id Freq ID2 PSC
0 a1 0 xy 33
1 yz 35
2 a1 1 xz 60
3 a2 0 pq 70
5 rs 80
4 a2 1 qr 75
Note that this denaturates your data, so you should only do this for display purposes.
Another option, set the columns as MultiIndex:
df.set_index(['Id', 'Freq']).sort_index()
The display will hide the consecutive duplicates, not exactly the way you want though.
CodePudding user response:
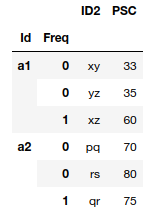
You can have a look at the Pandas functions set_index and sort_index. For your specific problem let's say that you have a dataset called df
df.set_index(['Id','Freq'])
will give you
ID2 PSC
Id Freq
a1 0 xy 33
0 yz 35
1 xz 60
a2 0 pq 70
1 qr 75
0 rs 80
Then you can decide if you want to sort by the specific index of your choice (to get unique values).