I am trying to understand how linear modelling can be used to as an alternative to the t-test when analysing gene expression data. For a single gene, I have a dataframe of 20 gene expression values altogether in group 1 (n=10) and group 2 (n=10).
gexp = data.frame(expression = c(2.7,0.4,1.8,0.8,1.9,5.4,5.7,2.8,2.0,4.0,3.9,2.8,3.1,2.1,1.9,6.4,7.5,3.6,6.6,5.4),
group = c(rep(1, 10), rep(2, 10)))
The data can be (box)plotted using ggplot as shown below:
plot <- gexp %>%
ggplot(aes(x = group, y = expression))
geom_boxplot()
geom_point()
plot
I wish to model the expression in groups 1 and 2 using the regression formula: Y = Beta0 (Beta1 x X) e where Y is the expression I want to model and X represents the two groups that are encoded as 0 and 1 respectively. Therefore, the expression in group 1 (when x = 0) is equal to Beta0; and the expression in group 2 (when x = 1) is equal to Beta0 Beta1. If this is modelled with:
mod1 <- lm(expression ~ group, data = gexp)
mod1
The above code outputs an intercept of 2.75 and a slope of 1.58. It is the visualisation of the linear model that I don't understand. I would be grateful for a clear explanation of the below code:
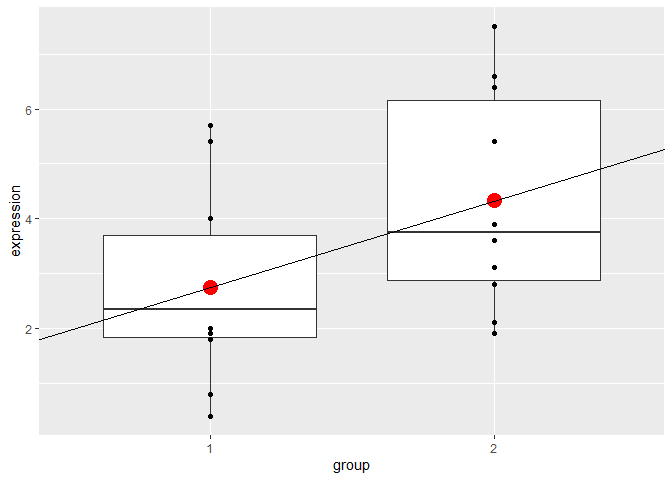
plot
geom_point(data = data.frame(x = c(1, 2), y = c(2.75, 4.33)),
aes(x = x, y = y),
colour = "red", size = 5)
geom_abline(intercept = coefficients(mod1)[1] - coefficients(mod1)[2],
slope = coefficients(mod1)[2])
I get why the data.frame values are the ones chosen (the value of 4.33 is the sum of the intercept, Beta0 and the slope, Beta1) , but it is the geom_abline arguments I do not understand. Why is the intercept calculation as shown? In the text I am using it states, '...we need to subtract the slope from the intercept when plotting the linear model because groups 1 and 2 are encoded as 0 and 1 in the model, but plotted as 1 and 2 on the figure.' I don't follow this point and would be grateful for an explanation, without getting too technical.
CodePudding user response:
I believe your code is correct if the group variable was encoded as a factor.
library(ggplot2)
gexp = data.frame(expression = c(2.7,0.4,1.8,0.8,1.9,5.4,5.7,2.8,2.0,4.0,3.9,2.8,3.1,2.1,1.9,6.4,7.5,3.6,6.6,5.4),
group = factor(c(rep(1, 10), rep(2, 10))))
plot <-
ggplot(gexp, aes(x = group, y = expression))
geom_boxplot()
geom_point()
mod1 <- lm(expression ~ group, data = gexp)
plot
geom_point(data = data.frame(x = c(1, 2), y = c(2.75, 4.33)),
aes(x = x, y = y),
colour = "red", size = 5)
geom_abline(intercept = coefficients(mod1)[1] - coefficients(mod1)[2],
slope = coefficients(mod1)[2])
Created on 2022-03-30 by the reprex package (v2.0.1)
To understand the difference between factors and integers in specifying linear models, you can have a look at the model matrix.
model.matrix(y ~ f, data = data.frame(f = 1:3, y = 1))
#> (Intercept) f
#> 1 1 1
#> 2 1 2
#> 3 1 3
#> attr(,"assign")
#> [1] 0 1
model.matrix(y ~ f, data = data.frame(f = factor(1:3), y = 1))
#> (Intercept) f2 f3
#> 1 1 0 0
#> 2 1 1 0
#> 3 1 0 1
#> attr(,"assign")
#> [1] 0 1 1
#> attr(,"contrasts")
#> attr(,"contrasts")$f
#> [1] "contr.treatment"
Created on 2022-03-30 by the reprex package (v2.0.1)
In the first model matrix, what you specify is what you get: you're modelling something as a function of the intercept and the f variable. In this model, you account for that f = 2 is twice as much as f = 1.
This works a little bit differently when f is a factor. A k-level factor gets split up in k-1 dummy variables, where each dummy variable encodes with 1 or 0 whether it deviates from the reference level (the first factor level). By modelling it in this way, you don't consider that the 2nd factor level might be twice the 1st factor level.
Because in ggplot2, the first factor level is displayed at position = 1 and not at position = 0 (how it is modelled), your calculated intercept is off. You need to subtract 1 * slope from the calculated intercept to get it to display right in ggplot2.