I am doing trading in a real time website. Now I want to scrap it continuously to extract real time stock or currency data for calculations using selenium and python. How do I approach the same. The webpage data is getting updated continuously and shown in the attached image in highlighted colours. Every time the data changes I should be able to extract it and do some calculations in the code. Pls help me to achieve the same.
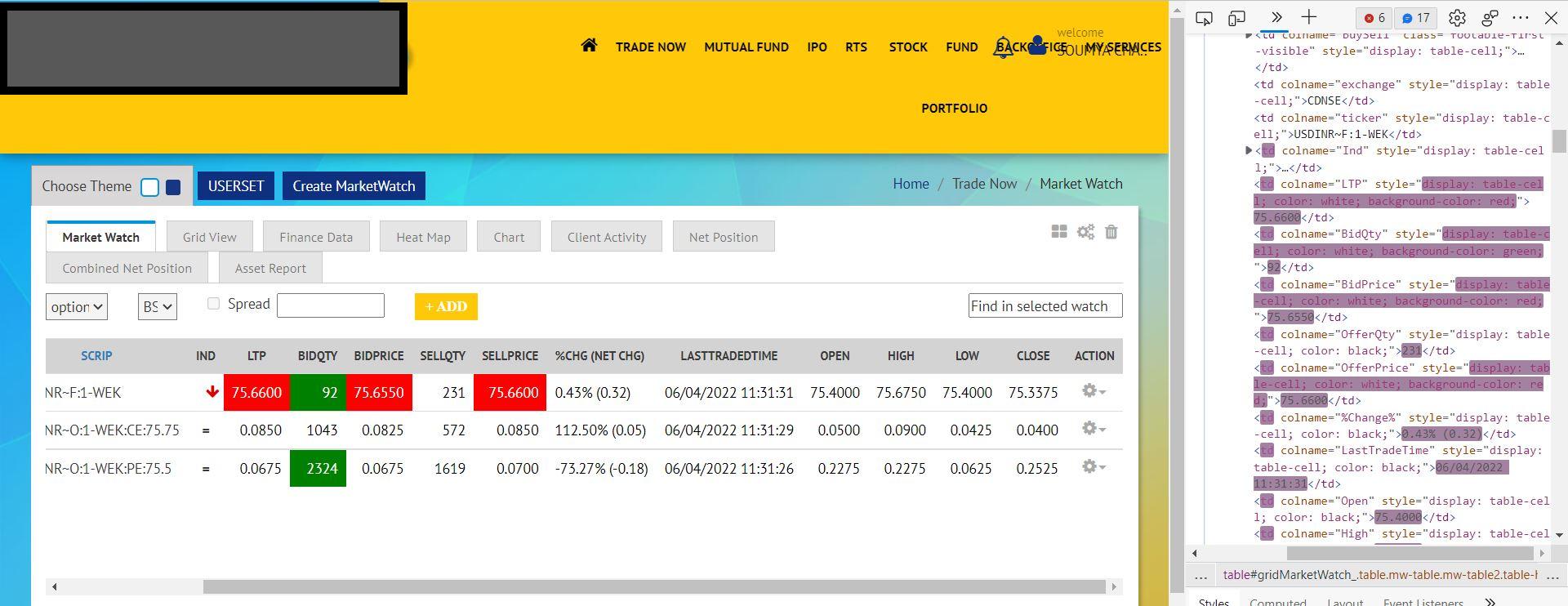
CodePudding user response:
to capture the dynamically changing value of Nifty50 for the 1D segment.
You should use the below XPath:
//button[text()='1D']/ancestor::nav//following-sibling::section/descendant::a[text()='Nifty 50']/../following-sibling::td/span
Your effective code would be:
driver.maximize_window()
wait = WebDriverWait(driver, 20)
driver.get('https://in.investing.com/')
i = 0
while True:
time.sleep(5)
oneD_Nifty50 = wait.until(EC.visibility_of_element_located((By.XPATH, "//button[text()='1D']/ancestor::nav//following-sibling::section/descendant::a[text()='Nifty 50']/../following-sibling::td/span")))
print(oneD_Nifty50.text)
i = i 1
if i == 10:
break
else:
continue
Imports:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
Output:
17,828.80
17,828.65
17,828.40
17,828.70
17,828.70
17,827.20
17,827.70
17,827.70
17,828.80
17,828.80
Process finished with exit code 0