I am getting the desired results but I'm not sure how to extract the percentage value from the listing as it doesn't have a class.
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
data =[]
def getdata (url):
header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(url, headers=header)
amazon_html = urllib.request.urlopen(req).read()
a_soup = soup(amazon_html,'html.parser')
for e in a_soup.select('div[data-component-type="s-search-result"]'):
try:
title = e.find('h2').text
except:
title = None
try:
sponsored = e.find('span',{'class':'a-color-secondary'}).text
except:
sponsored = None
try:
limited_deal = e.find('span',{'class':'a-badge-label-inner a-text-ellipsis'}).find('span', {'class': 'a-badge-text'}).text
except:
limited_deal = None
data.append({
'list_price':list_price,
'sponsored':sponsored,
'limited_deal':limited_deal
})
return a_soup
def getnextpage(a_soup):
try:
page = a_soup.find('a',attrs={"class": 's-pagination-item s-pagination-next s-pagination-button s-pagination-separator'})['href']
url = 'http://www.amazon.in' str(page)
except:
url = None
return url
keywords = ['earphones']
for k in keywords:
url = 'https://www.amazon.in/s?k=' k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
print(url)
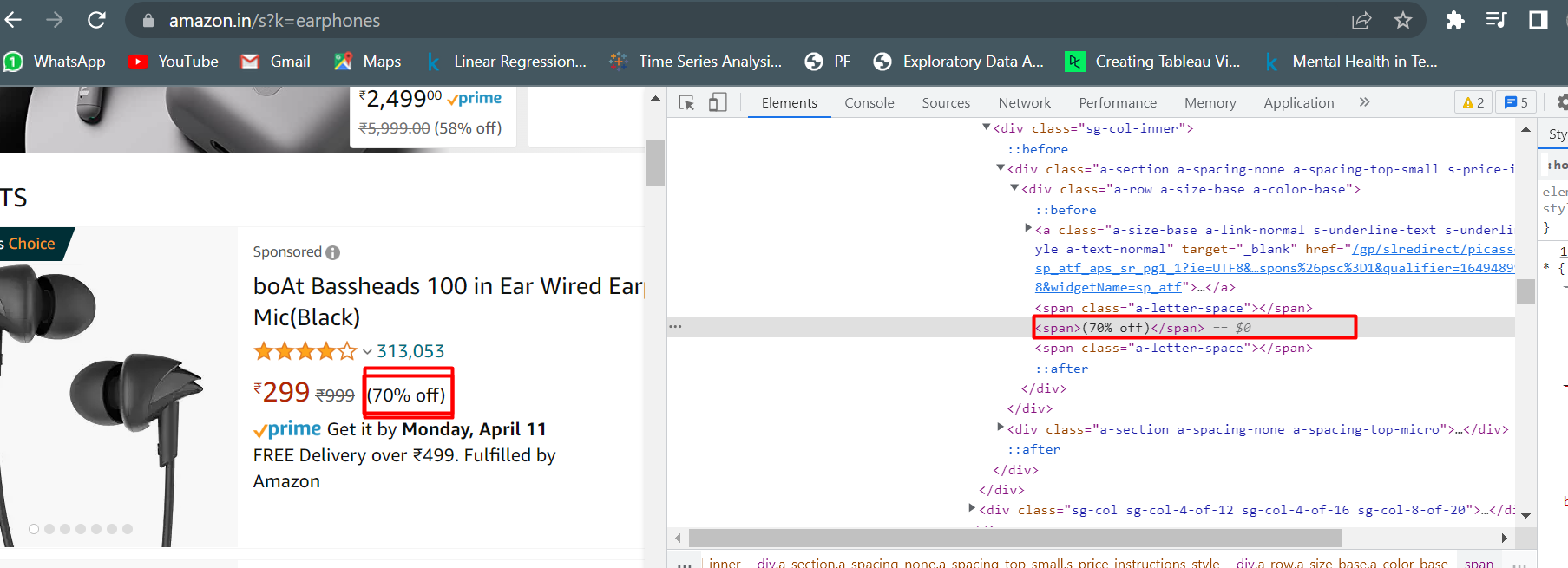
How do I get the discount (% off ). I have not written any code for that yet, rest of the results are showing up correctly
<
CodePudding user response:
You can get discounted price from span
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
data =[]
def getdata (url):
header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(url, headers=header)
amazon_html = urllib.request.urlopen(req).read()
a_soup = soup(amazon_html,'html.parser')
for e in a_soup.select('div[data-component-type="s-search-result"]'):
try:
title = e.find('h2').text
except:
title = None
try:
sponsored = e.find('span',{'class':'a-color-secondary'}).text
except:
sponsored = None
try:
limited_deal = e.find('span',{'class':'a-badge-label-inner a-text-ellipsis'}).find('span', {'class': 'a-badge-text'}).text
except:
limited_deal = None
try:
list_price = e.select_one('.a-letter-space span').text
print(list_price)
except:
limited_deal = None
data.append({
#'list_price':list_price,
'sponsored':sponsored,
'limited_deal':limited_deal
})
return a_soup
def getnextpage(a_soup):
try:
page = a_soup.find('a',attrs={"class": 's-pagination-item s-pagination-next s-pagination-button s-pagination-separator'})['href']
url = 'http://www.amazon.in' str(page)
except:
url = None
return url
keywords = ['earphones']
for k in keywords:
url = 'https://www.amazon.in/s?k=' k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
#print(url)
Output:
(70% off)
(56% off)
(70% off)
(70% off)
(63% off)
(25% off)
(53% off)
(50% off)
(63% off)
(43% off)
(57% off)
(62% off)
(50% off)
(60% off)
(69% off)
(50% off)
(41% off)
(60% off)
(70% off)
... so on
If you need only digit
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
data =[]
def getdata (url):
header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(url, headers=header)
amazon_html = urllib.request.urlopen(req).read()
a_soup = soup(amazon_html,'html.parser')
for e in a_soup.select('div[data-component-type="s-search-result"]'):
try:
title = e.find('h2').text
except:
title = None
try:
sponsored = e.find('span',{'class':'a-color-secondary'}).text
except:
sponsored = None
try:
limited_deal = e.find('span',{'class':'a-badge-label-inner a-text-ellipsis'}).find('span', {'class': 'a-badge-text'}).text
except:
limited_deal = None
try:
list_price = e.select_one('.a-letter-space span').text.split('%')[0].replace('(','')
print(list_price)
except:
limited_deal = None
data.append({
#'list_price':list_price,
'sponsored':sponsored,
'limited_deal':limited_deal
})
return a_soup
def getnextpage(a_soup):
try:
page = a_soup.find('a',attrs={"class": 's-pagination-item s-pagination-next s-pagination-button s-pagination-separator'})['href']
url = 'http://www.amazon.in' str(page)
except:
url = None
return url
keywords = ['earphones']
for k in keywords:
url = 'https://www.amazon.in/s?k=' k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
#print(url)
Output:
70
56
70
70
63
25
53
50
63
50
57
62
60
69
50
43
60
70
41
61
53
61
57
53
61
70
70
60
75
57
75
18
62
61
38
60
80
71
70
60
81
47
70
53
57
62
53
64
57
37
80
42
83
55
53
78
63
CodePudding user response:
You could use a css selector .a-letter-space span with BeautifulSoup's select method and loop through the result to extract the discount text
Here is a sample code:
import requests
from bs4 import BeautifulSoup
def extract_discount(discount_str):
"""
Extract discount from an unformatted
discount string like: (70% off)
Returns: number extracted as string. Ex: 70
"""
return discount_str.text.split('%')[0].replace('(','')
# using googlebot's user agent
headers = {
'User-Agent': 'Mozilla/5.0 AppleWebKit/27.0.1453 (KHTML, like Gecko; compatible; Googlebot/2.1; http://www.google.com/bot.html) Safari/27.0.1453'
}
res = requests.get('https://www.amazon.in/s?k=earphones', headers=headers)
soup = BeautifulSoup(res.content, 'html.parser')
for discount in soup.select('.a-letter-space span'):
# just remove extract_discount if you just want (70% off)
print(extract_discount(discount))