I'm currently trying to create a column in a pandas dataframe, that creates a counter that equals the number of rows in the dataframe, divided by 2. Here is my code so far:
# Fill the cycles column with however many rows exist / 2
for x in ((jac_output.index)/2):
jac_output.loc[x, 'Cycles'] = x 1
However, I've noticed that it misses out values every so often, like this:
[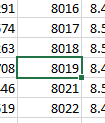
Why would my counter miss a value every so often as it gets higher? And is there another way of optimizing this, as it seems to be quite slow?
CodePudding user response:
you may have removed some data from the dataframe, so some indicies are missing, therefore you should use reset_index to renumber them, or you can just use
for x in np.arange(0,len(jac_output.index),1)/2:.
CodePudding user response:
You can view jac_output.index as a list like [0, 1, 2, ...]. When you divide it by 2, it results in [0, 0.5, 1, ...]. 0.5 is surely not in your original index.
To slice the index into half, you can try:
jac_output.index[:len(jac_output.index)//2]