I'm trying to add two additional rows to a data frame, each row sums the matches in the 'Type' column, I want the first column to search for the string 'car' in Type and the second for 'truck'. In excel I'd use a SUMIF function, is it possible to do with pandas and groupby or another method?
import pandas as pd
df = pd.DataFrame({
'Type': ['red car','blue car','yellow car', 'red truck', 'blue truck', 'yellow truck'],
'California':[3,10,9,1,9,4],
'New York':[1,6,1,10,7,10],
'Georgia':[3,3,8,6,9,1]
})
cars = df['Type'].str.contains('car', case=False, na=False).sum() #as far as I've got
CodePudding user response:
Somethin' like that:
# create a group col com 'car' and 'truck' values
df['group'] = df.Type.apply(lambda x: x.split()[1])
# grouping them values in a new df
df_group = df.groupby('group',as_index=False)[['California', 'New York',
'Georgia']].sum().rename(columns={
'group': 'Type'})
# concat both df and df_group
df_result = pd.concat([df, df2]).drop('group', axis=1).set_index('Type')
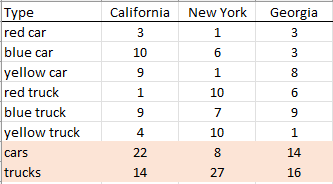
df_result:
California New York Georgia
Type
red car 3 1 3
blue car 10 6 3
yellow car 9 1 8
red truck 1 10 6
blue truck 9 7 9
yellow truck 4 10 1
car 22 8 14
truck 14 27 16
I hope this snippet help you
CodePudding user response:
Try this:
pd.concat([df,
df.groupby(df['Type'].str.split(' ').str[-1]).sum().reset_index()],
ignore_index=True)
Output:
Type California New York Georgia
0 red car 3 1 3
1 blue car 10 6 3
2 yellow car 9 1 8
3 red truck 1 10 6
4 blue truck 9 7 9
5 yellow truck 4 10 1
6 car 22 8 14
7 truck 14 27 16
Details:
You can use .str accessor to split your Type into two parts color and vehicle, then slice that list and get the last value, vehicle, with .str[-1]. Use this vehicle series to groupby your dataframe and sum. Lastly, pd.concat the results of the groupby sum with your original dataframe.