I have a dataframe that contains multiple columns and would like to randomly select an equal number of rows based on the values of specific column. I thought of using a df.groupby['...'] but it did not work. Here is an example:
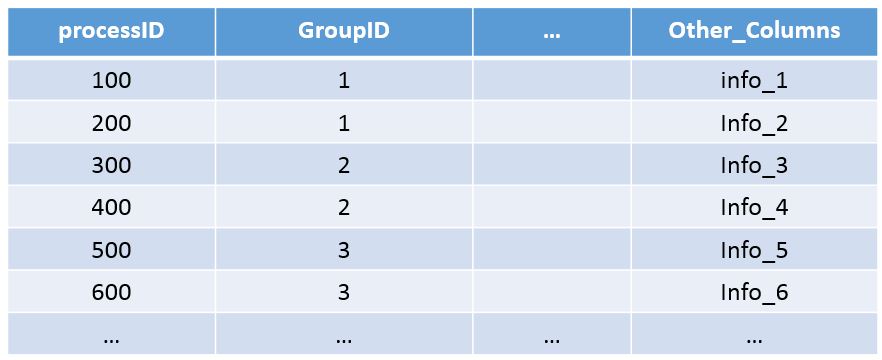
Assume that I would like to randomly select one row per GroupID, how can I accomplish this? For example, let's say I select one random row per GroupID, the result would yield the following:
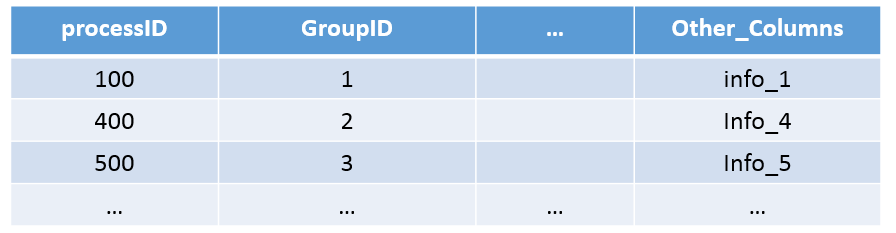
such that it outputs a single row based on the values in GroupID. Assume, for example, that rows are sorted by GroupID (from asc to desc), then select an "n" number of rows from ones that pertain to GroupID 1, 2, 3, and so on. Any information would definitely be helpful.
Also, if I need to select a specific number of rows per GroupID (let's say 1 row for GroupID=100, 4 rows for GroupID=200, etc.), any ideas?
[update] I made a minor revision or extension using the recommended answer below to selectively choose specific n values for each group using the following:
samples = []
values = [1, 1, 2, ...]
index = 0
for group in df.GroupID.unique():
s = df.loc[df.GroupID== group].sample(n=values[index ]).reset_index(drop=True)
samples.append(s)
index = index 1
sample = pd.concat(samples, axis=0)
CodePudding user response:
I hope this code snippet will work for you
samples = []
for group in df.GroupID.unique():
s = df.loc[df.GroupID== group].sample(n=1).reset_index(drop=True)
samples.append(s)
sample = pd.concat(samples, axis=0)
The code will take each 'GroupID' and sample observation from that subgroup. You can concatenate the subsamples (with one GroupID) for the needed sample.