The question I am trying to answer is how can I return the correct order and sequence of weeks for each ID? For example, while it is true the first week for each ID will always start at 1 (its the first week in the series), it could be the following date in the series may also be within the first week (e.g., so should return 1 again) or perhaps be a date that falls in the 3rd week (e.g., so should return 3).
The code I've written so far is:
select distinct
row_number() over (partition by ID group by date) row_nums
,ID
,date
from table_a
Which simply returns the running tally of dates by ID, and doesn't take into account what week number that date falls in.
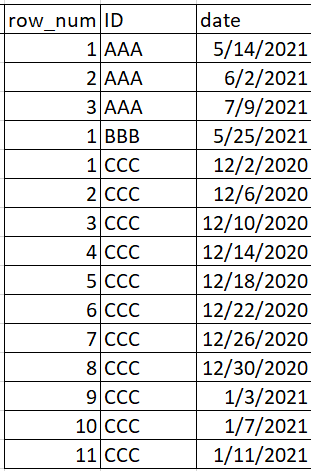
But what I'm looking for is this:
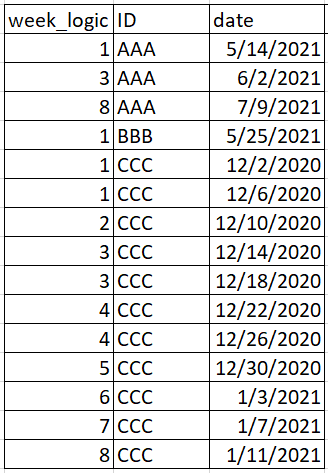
Here's some setup code to assist:
CREATE TABLE random_table
(
ID VarChar(50),
date DATETIME
);
INSERT INTO random_table
VALUES
('AAA',5/14/2021),
('AAA',6/2/2021),
('AAA',7/9/2021),
('BBB', 5/25/2021),
('CCC', 12/2/2020),
('CCC',12/6/2020),
('CCC',12/10/2020),
('CCC',12/14/2020),
('CCC',12/18/2020),
('CCC',12/22/2020),
('CCC',12/26/2020),
('CCC',12/30/2020),
('CCC',1/3/2021),
('DDD',1/7/2021),
('DDD',1/11/2021)
CodePudding user response:
with adj as (
select *, dateadd(day, -1, "date") as adj_dt
from table_a
)
select
datediff(week,
min(adj_dt) over (partition by id),
adj_dt) 1 as week_logic,
id, "date"
from adj
This assumes that your idea of weeks corresponds with @@datefirst set as Sunday. For a Sunday to Saturday definition you would find 12/06/2020 and 12/10/2020 in the same week, so presumably you want something like a Monday start instead (which also seems to line up with the numbering for 12/02/2020, 12/14/2020 and 12/18/2020.) I'm compensating by sliding backward a day in the weeks calculation. That step could be handled inline without a CTE but perhaps it illustrates the approach more clearly.
CodePudding user response:
Your objective isn't clear but I think you would benefit from a Tally-Table of the weeks and then LEFT JOIN to your source data. This will give you a row for each week AND source data if it exists
CodePudding user response:
SELECT
CASE WHEN ROW_NUMBER() OVER (PARTITION BY ID ORDER BY [date])=1 THEN 1
ELSE DATEPART(WK, (DATE) ) - DATEPART(WK, FIRST_VALUE([DATE]) OVER (PARTITION BY ID ORDER BY [date])) END PD,
ID,
CONVERT(VARCHAR(10), [date],120)
FROM random_table rt
ORDER BY ID,[date]
output:
| PD | ID | (No column name) |
|---|---|---|
| 1 | AAA | 2021-05-14 |
| 3 | AAA | 2021-06-02 |
| 8 | AAA | 2021-07-09 |
| 1 | BBB | 2021-05-25 |
| 1 | CCC | 2020-12-02 |
| 1 | CCC | 2020-12-06 |
| 1 | CCC | 2020-12-10 |
| 2 | CCC | 2020-12-14 |
| 2 | CCC | 2020-12-18 |
| 3 | CCC | 2020-12-22 |
| 3 | CCC | 2020-12-26 |
| 4 | CCC | 2020-12-30 |
| -47 | CCC | 2021-01-03 |
| 1 | DDD | 2021-01-07 |
| 1 | DDD | 2021-01-11 |
- Dates are in the format
YYYY-MM-DD. - I will leave the
-47in here, so you can fix it yourself (as an exercise)