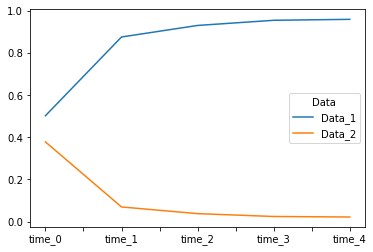
I have a data frame (loading from CSV) file that looks like below one
Data Mean sd time__1 time__2 time__3 time__4 time__5
0 Data_1 0.947667 0.025263 0.501517 0.874750 0.929426 0.953847 0.958375
1 Data_2 0.031960 0.017314 0.377588 0.069185 0.037523 0.024028 0.021532
Now, I wanted to plot 2 time series plots for (data_1, data_2) with (time__1, time__2, etc) as a timepoint. The x axis is (time__1, time__2, etc) and the y axis is their associated values.
The code I am trying
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("file.csv", delimiter=',', header=0)
data = data.drop(["Unnamed: 0"], axis=1)
# Set the date column as the index
data = data.set_index(["time__1", "time__2", "time__3", "time__4", "time__5"])
ax = data.plot(linewidth=2, fontsize=12)
ax.set_xlabel('Data')
ax.legend(fontsize=12)
plt.savefig("series.png")
plt.show()
The figure I am getting is not as expected.
I think I am doing some wrong with set_index() as my time points are in different columns.
How can I plot time-series when time points are in different columns?
Reproducible data as dictionary formate
{'Data': {(0.501517236232758, 0.874750375747681, 0.929425954818726, 0.953846752643585, 0.958374977111816): 'Data_1', (0.377588421106338, 0.069185301661491, 0.037522859871388, 0.0240284409374, 0.021532088518143): 'Data_2'}, 'Mean': {(0.501517236232758, 0.874750375747681, 0.929425954818726, 0.953846752643585, 0.958374977111816): 0.947667360305786, (0.377588421106338, 0.069185301661491, 0.037522859871388, 0.0240284409374, 0.021532088518143): 0.031959813088179}, 'sd': {(0.501517236232758, 0.874750375747681, 0.929425954818726, 0.953846752643585, 0.958374977111816): 0.025263005867601, (0.377588421106338, 0.069185301661491, 0.037522859871388, 0.0240284409374, 0.021532088518143): 0.017313838005066}}
CodePudding user response:
IIUC you are getting the index wrong: If time__1, time__2 etc. is supposed to be your x-axis, that's what you want your index to be. The plot data series names are the columns. Therefore, you need to transpose your DataFrame. Using the csv data in your first table:
print(df)
# out:
Data Mean sd time__1 time__2 time__3 time__4 \
0 Data_1 0.947667 0.025263 0.501517 0.874750 0.929426 0.953847
1 Data_2 0.031960 0.017314 0.377588 0.069185 0.037523 0.024028
time__5
0 0.958375
1 0.021532
Changing column names and transposing:
df.drop(["Mean", "sd"], axis=1).set_index("Data").T
yields an appropriately formatted dataframe:
Data Data_1 Data_2
time__1 0.501517 0.377588
time__2 0.874750 0.069185
time__3 0.929426 0.037523
time__4 0.953847 0.024028
time__5 0.958375 0.021532
which can simply be plotted:
df.plot()