I have a data frame below and i want to choose the first non missing date by each row and add it as a new column to the data frame.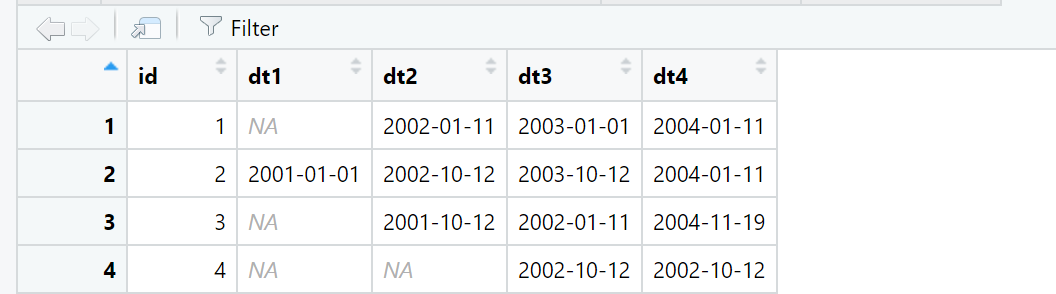
CodePudding user response:
You can use {dplyr}
data <- data.frame(x = c(NA, 1), y = 2:3)
library(dplyr, warn.conflicts = FALSE)
data %>% mutate(z = coalesce(!!!.))
#> x y z
#> 1 NA 2 2
#> 2 1 3 1
Created on 2022-04-20 by the reprex package (v2.0.1)
CodePudding user response:
A base R option:
df$dt5 <- apply(df[,-1], 1, function(z) na.omit(z)[1])
df
Output:
id dt1 dt2 dt3 dt4 dt5
1 1 <NA> 2002-01-11 2003-01-01 2004-01-11 2002-01-11
2 2 2001-01-01 2002-10-12 2003-10-12 2004-01-11 2001-01-01
3 3 <NA> 2001-10-12 2002-01-11 2004-11-19 2001-10-12
4 4 <NA> <NA> 2002-10-12 2002-10-12 2002-10-12
Your data:
df <- data.frame(id = c(1,2,3,4),
dt1 = c(NA, "2001-01-01", NA, NA),
dt2 = c("2002-01-11", "2002-10-12", "2001-10-12", NA),
dt3 = c("2003-01-01", "2003-10-12", "2002-01-11", "2002-10-12"),
dt4 = c("2004-01-11", "2004-01-11", "2004-11-19", "2002-10-12"))
CodePudding user response:
We could do it with pivoting: Data from Quinten, many thanks!
library(dplyr)
library(tidyr)
df %>%
pivot_longer(
-id,
) %>%
group_by(id) %>%
mutate(first = first(na.omit(value))) %>%
pivot_wider(
names_from = name
)
id first dt1 dt2 dt3 dt4
<dbl> <chr> <chr> <chr> <chr> <chr>
1 1 2002-01-11 NA 2002-01-11 2003-01-01 2004-01-11
2 2 2001-01-01 2001-01-01 2002-10-12 2003-10-12 2004-01-11
3 3 2001-10-12 NA 2001-10-12 2002-01-11 2004-11-19
4 4 2002-10-12 NA NA 2002-10-12 2002-10-12