I'm playing about with working with a dictionary and and adding the contents of it within an existing csv file. This is what I have so far:
List<string> files = new List<string>();
files.Add("test1");
files.Add("test2");
Dictionary<string, List<string>> data = new Dictionary<string, List<string>>();
data.Add("Test Column", files.ToList());
foreach ( var columnData in data.Keys)
{
foreach (var rowData in data[columnData])
{
var csv = File.ReadLines(filePath.ToString()).Select((line, index) => index == 0
? line "," columnData.ToString()
: line "," rowData.ToString()).ToList();
File.WriteAllLines(filePath.ToString(), csv);
}
}
This sort of works but not the way I'm intending. What I would like the output to be is something along the lines
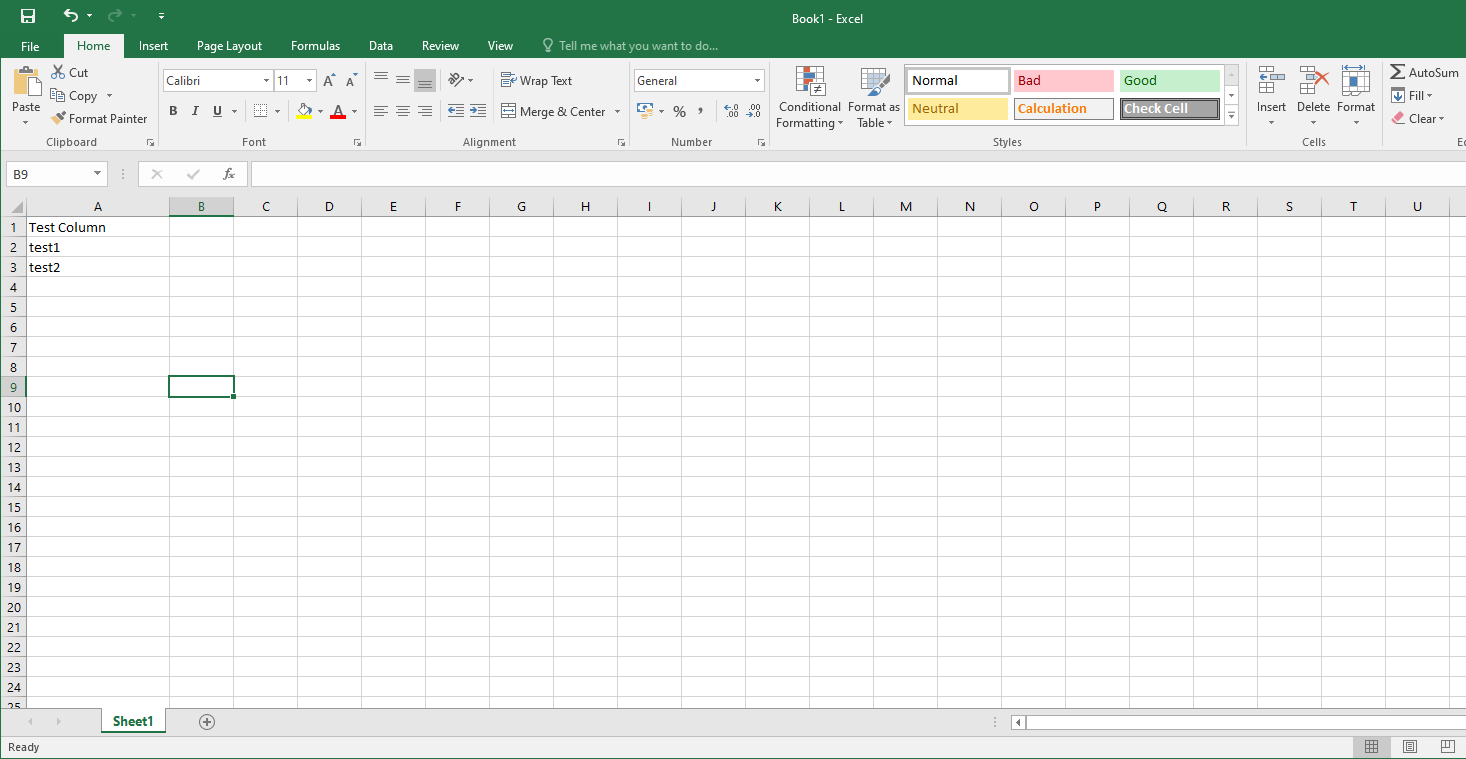
but what I'm actually getting is:
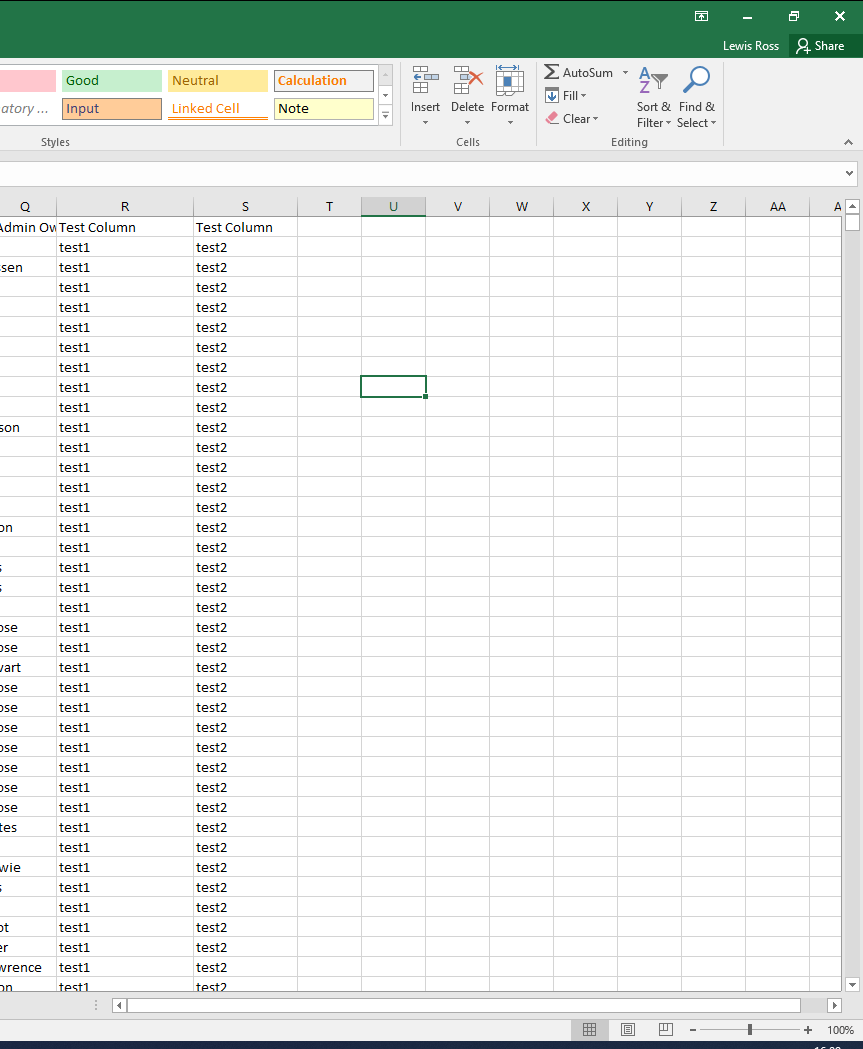
as you'll be able to see I'm getting 2 columns instead of just 1 with a column each for both list values and the values repeating on every single row. How can I fix it so that it's like how I've got in the first image? I know it's something to do with my foreach loop and the way I'm inputting the data into the file but I'm just not sure how to fix it
Edit:
So I have the read, write and AddToCsv methods and when I try it like so:
File.WriteAllLines("file.csv", new string[] { "Col0,Col1,Col2", "0,1,2", "1,2,3", "2,3,4", "3,4,5" });
var filePath = "file.csv";
foreach (var line in File.ReadLines(filePath))
Console.WriteLine(line);
Console.WriteLine("\n\n");
List<string> files = new List<string>() { "test1", "test2" };
List<string> numbers = new List<string>() { "one", "two", "three", "four", "five" };
Dictionary<string, List<string>> newData = new Dictionary<string, List<string>>() {
{"Test Column", files},
{"Test2", numbers}
};
var data1 = ReadCsv(filePath);
AddToCsv(data1, newData);
WriteCsv(filePath.ToString(), data1);
It works perfectly but when I have the file path as an already created file like so:
var filePath = exportFile.ToString();
I get the error:
Message :Index was out of range. Must be non-negative and less than the size of the collection. (Parameter 'index')
Source :System.Private.CoreLib
Stack : at System.Collections.Generic.List1.get_Item(Int32 index) at HMHExtract.Runner.ReadCsv(String path) in C:\tfs\Agility\Client\HMH Extract\HMHExtract\Runner.cs:line 194 at HMHExtract.Runner.Extract(Nullable1 ct) in C:\tfs\Agility\Client\HMH Extract\HMHExtract\Runner.cs:line 68
Target Site :Void ThrowArgumentOutOfRange_IndexException()
The lines in question are:
line 194 - var col = colNames[i]; of the ReadCsv method line 68 - var data1 = ReadCsv(filePath);
Edit:
So after debugging I've figured out where the issue has come from.
In the csv I am trying to update there are 17 columns so obviously 17 rows of values. So the colNames count is 17. csvRecord Count = 0 and i goes up to 16.
However when it reaches a row where in one of the fields there are 2 values separated by a comma, it counts it s 2 row values instead of just 1 so for the row value instead of being string{17} it becomes string{18} and that causes the out of range error.
To clarify, for the row it gets to which causes the error one of the fields has the values Chris Jones, Malcolm Clark. Now instead of counting them as just 1 row, the method counts them as 2 separate ones, how can I change so it doesn't count them as 2 separate rows?
CodePudding user response:
The best way is to read the csv file first into a list of records, and then add columns to each record. A record is a single row of the csv file, read as a Dictionary<string, string>. The keys of this dict are the column names, and the values are the elements of the row in that column.
public static void AddToCsv(string path, Dictionary<string, List<string>> newData)
{
var fLines = File.ReadLines(path);
var colNames = fLines.First().Split(',').ToList(); // col names in first line
List<Dictionary<string, string>> rowData = new List<Dictionary<string, string>>(); // A list of records for all other rows
foreach (var line in fLines.Skip(1)) // Iterate over second through last lines
{
var row = line.Split(',');
Dictionary<string, string> csvRecord = new Dictionary<string, string>();
// Add everything from this row to the record dictionary
for (int i = 0; i < row.Length; i )
{
var col = colNames[i];
csvRecord[col] = row[i];
}
rowData.Add(csvRecord);
}
// Now, add new data
foreach (var newColName in newData.Keys)
{
var colData = newData[newColName];
for (int i = 0; i < colData.Count; i )
{
if (i < rowData.Count) // If the row record already exists, add the new column to it
rowData[i].Add(newColName, colData[i]);
else // Add a row record with only this column
rowData.Add(new Dictionary<string, string>() { {newColName, colData[i]} });
}
colNames.Add(newColName);
}
// Now, write all the data
StreamWriter sw = new StreamWriter(path);
// Write header
sw.WriteLine(String.Join(",", colNames));
foreach (var row in rowData)
{
var line = new List<string>();
foreach (var colName in colNames) // Iterate over columns
{
if (row.ContainsKey(colName)) // If the row contains this column, add it to the line
line.Add(row[colName]);
else // Else add an empty string
line.Add("");
}
// Join all elements in the line with a comma, then write to file
sw.WriteLine(String.Join(",", line));
}
sw.Close();
}
To use this, let's create the following CSV file file.csv:
Col0,Col1,Col2
0,1,2
1,2,3
2,3,4
3,4,5
List<string> files = new List<string>() {"test1", "test2"};
List<string> numbers = new List<string>() {"one", "two", "three", "four", "five"};
Dictionary<string, List<string>> newData = new Dictionary<string, List<string>>() {
{"Test Column", files},
{"Test2", numbers}
}
AddToCsv("file.csv", newData);
And this results in file.csv being modified to:
Col0,Col1,Col2,Test Column,Test2
0,1,2,test1,one
1,2,3,test2,two
2,3,4,,three
3,4,5,,four
,,,,five
To make this more organized, I defined a struct CsvData to hold the column names and row records, and a function ReadCsv() that reads the file into this struct, and WriteCsv() that writes the struct to a file. Then separate responsibilities -- ReadCsv() only reads the file, WriteCsv() only writes the file, and AddToCsv() only adds to the file.
public struct CsvData
{
public List<string> ColNames;
public List<Dictionary<string, string>> RowData;
}
public static CsvData ReadCsv(string path)
{
List<string> colNames = new List<string>();
List<Dictionary<string, string>> rowData = new List<Dictionary<string, string>>(); // A list of records for all other rows
if (!File.Exists(path)) return new CsvData() {ColNames = colNames, RowData = rowData };
var fLines = File.ReadLines(path);
var firstLine = fLines.FirstOrDefault(); // Read the first line
if (firstLine != null) // Only try to parse the file if the first line actually exists.
{
colNames = firstLine.Split(',').ToList(); // col names in first line
foreach (var line in fLines.Skip(1)) // Iterate over second through last lines
{
var row = line.Split(',');
Dictionary<string, string> csvRecord = new Dictionary<string, string>();
// Add everything from this row to the record dictionary
for (int i = 0; i < row.Length; i )
{
var col = colNames[i];
csvRecord[col] = row[i];
}
rowData.Add(csvRecord);
}
}
return new CsvData() {ColNames = colNames, RowData = rowData};
}
public static void WriteCsv(string path, CsvData data)
{
StreamWriter sw = new StreamWriter(path);
// Write header
sw.WriteLine(String.Join(",", data.ColNames));
foreach (var row in data.RrowData)
{
var line = new List<string>();
foreach (var colName in data.ColNames) // Iterate over columns
{
if (row.ContainsKey(colName)) // If the row contains this column, add it to the line
line.Add(row[colName]);
else // Else add an empty string
line.Add("");
}
// Join all elements in the line with a comma, then write to file
sw.WriteLine(String.Join(",", line));
}
sw.Close();
}
public static void AddToCsv(CsvData data, Dictionary<string, List<string>> newData)
{
foreach (var newColName in newData.Keys)
{
var colData = newData[newColName];
for (int i = 0; i < colData.Count; i )
{
if (i < data.RowData.Count) // If the row record already exists, add the new column to it
data.RowData[i].Add(newColName, colData[i]);
else // Add a row record with only this column
data.RowData.Add(new Dictionary<string, string>() { {newColName, colData[i]} });
}
data.ColNames.Add(newColName);
}
}
Then, to use this, you do:
var data = ReadCsv(path);
AddToCsv(data, newData);
WriteCsv(path, data);
CodePudding user response:
I managed to figure out a way that worked for me, might not be the most efficient but it does work. It involves using csvHelper
public static void AppendFile(FileInfo fi, List<string> newColumns, DataTable newRows)
{
var settings = new CsvConfiguration(new CultureInfo("en-GB"))
{
Delimiter = ";"
};
var dt = new DataTable();
using (var reader = new StreamReader(fi.FullName))
using (var csv = new CsvReader(reader, CultureInfo.InvariantCulture))
{
using (var dataReader = new CsvDataReader(csv))
{
dt.Load(dataReader);
foreach (var title in newColumns)
{
dt.Columns.Add(title);
}
dt.Rows.Clear();
foreach (DataRow row in newRows.Rows)
{
dt.Rows.Add(row.ItemArray);
}
}
}
using var streamWriter = new StreamWriter(fi.FullName);
using var csvWriter = new CsvWriter(streamWriter, settings);
// Write columns
foreach (DataColumn column in dt.Columns)
{
csvWriter.WriteField(column.ColumnName);
}
csvWriter.NextRecord();
// Write row values
foreach (DataRow row in dt.Rows)
{
for (var i = 0; i < dt.Columns.Count; i )
{
csvWriter.WriteField(row[i]);
}
csvWriter.NextRecord();
}
}
I start by getting the contents of the csv file into a data table and then adding in the new columns that I need. I then clear all the rows in the datatable and add new ones in (the data that is removed is added back in via the newRows parameter) and then write the datatable to the csv file