I have a dictionary file saved in .npy file that contain two cluster ids that i want to plot in a scatter plot(for the id values saved under key '0' one cluster and the id values saved under key '1' is another cluster)
My script:
import numpy as np
import matplotlib.pyplot as plt
data=np.load("dict.npy",allow_pickle=True)
print(data)
array({0: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 90, 91,
92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 125,
126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138,
139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151,
152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164,
165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177,
178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190,
191, 192, 193, 194, 195, 196, 197, 198, 199]), 1: array([ 89, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115,
116, 117, 118, 119, 120, 121, 122, 123, 124])}, dtype=object)
CodePudding user response:
An example as you have request:
#you will need these libraries:
import numpy as np
from sklearn.cluster import KMeans
from matplotlib import pyplot as plt
Then generate some random 2D data, just for this example:
#the data you want to cluster
X = np.random.multivariate_normal(mean=[1,2], cov=[[.5, .25], [.25,.75]], size=1800)
plt.scatter(*X.T, alpha=.25, color="k")
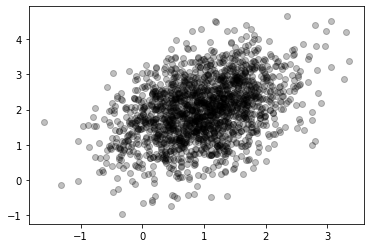
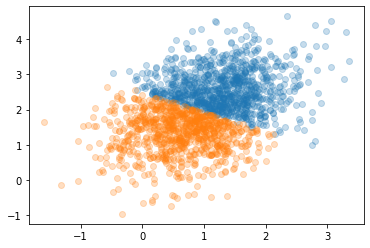
Finally run the clustering and see the result:
X_cluster = KMeans(n_clusters=2).fit_predict(X)
for c in set(X_cluster):
plt.scatter(*X[X_cluster==c].T, alpha=.25)
CodePudding user response:
plt.figure(figsize=(7,7))
for cluster in data:
plt.scatter(X[data[cluster],0], X[data[cluster],1])
plt.show()
where X is the dateset that you have used for the clustering and has shape (N,2) (N is the number of samples)