I am trying to create code that automatically creates data in the format below (for more background on the colspan see 
Calculating colspan/width
I want to calculate colspan and width (which is simply 50*colspan) based on the difference between the columns_used column and the following vector:
total_colspan = c(0, 25, 50, 100, 250, 500, 1000, 1500, 3000, "Infinity", "SUM")
As an example, for Name_a, the first colspan would be 1 (and width=50), because the first threshold is 0-25 for both vectors. However Name_a skips the number 50, so the next colspan should be 2 (and width=100).
Desired output:
row row freq width colspan
1 Name_a 5 50 1
2 Name_a 4 100 2
3 Name_a 3 100 2
4 Name_a 2 200 4
5 Name_a 14 50 1
6 Name_b 1 50 1
...
11 Name_b 7 50 1
Where the sum of colspan for each Name_x should be 10 in total and row_freq comes from the freq column in dat.
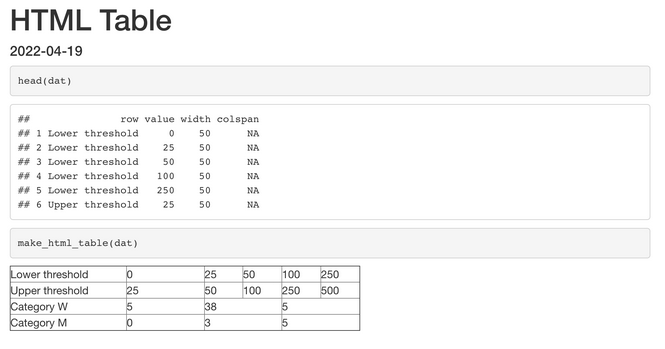
The idea is to use the desired output to create a hmtl table:
CodePudding user response:
It can certainly be improved, but here's a rough way to do it:
l <- lapply(dat$columns_used, \(y) sapply(y, \(x) which(total_colspan == x) - which(y == x)))
dat[1:2] %>%
unnest_longer(freq) %>%
mutate(colspan = unlist(lapply(l, \(x) diff(x) 1)),
width = colspan * 50)
# A tibble: 9 x 4
Name freq colspan width
<chr> <dbl> <dbl> <dbl>
1 Name_a 5 1 50
2 Name_a 4 2 100
3 Name_a 3 2 100
4 Name_a 2 4 200
5 Name_a 14 1 50
6 Name_b 1 1 50
7 Name_b 6 7 350
8 Name_b 0 1 50
9 Name_b 7 1 50
Note: \(x) is a shortcut for function(x).