Program workflow:
- Open "asigra_backup.txt" file and read each line
- Search for the exact string: "Errors: " {any value ranging from 1 - 100}. e.g "Errors: 12"
- When a match is found, open a separate .txt file in write&append mode
- Write the match found. Example: "Errors: 4"
- In addition to above write, append the next 4 lines below the match found in step 3; as that is additional log information What I've done:
- Tested a regular expressions that matches with my sample data on regex101.com
- Used list comprehension to find all matches in my test file Where I need help (please):
- Figuring out how to append additional 4 lines of log information below each match string found
CURRENT CODE:
result = [line.split("\n")[0] for line in open('asigra_backup.txt') if re.match('^Errors:\s([1-9]|[1-9][0-9]|100)',line)]
print(result)
CURRENT OUTPUT:
['Errors: 1', 'Errors: 128']
DESIRED OUTPUT:
Errors: 1
Pasta
Fish
Dog
Doctonr
Errors: 128
Lemon
Seasoned
Rhinon
Goat
SAMPLE .TXT FILE
Errors: 1
Pasta
Fish
Dog
Doctonr
Errors: 128
Lemon
Seasoned
Rhinon
Goat
Errors: 0
Rhinon
Cat
Dog
Fish
CodePudding user response:
Using better regex and re.findall can make it easier. In the following regex, all Errors: and 4 following lines are detected.
import re
regex_matches = re.findall('(?:[\r\n] |^)((Errors:\s*([1-9][0-9]?|100))(?:[\r\n\s\t] .*){4})', open('asigra_backup.txt', 'r').read())
open('separate.txt', 'a').write('\n' '\n'.join([i[0] for i in regex_matches]))
To access error numbers or error lines following lines can use:
error_rows = [i[1] for i in regex_matches]
error_numbers = [i[2] for i in regex_matches]
print(error_rows)
print(error_numbers)
CodePudding user response:
I wrote a code which prints the output as requested. The code will work when Errors: 1 line is added as last line. See the text I have parsed:
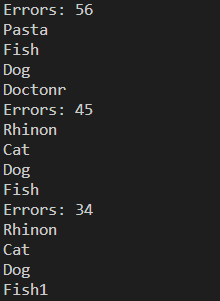
data_to_parse = """
Errors: 56
Pasta
Fish
Dog
Doctonr
Errors: 0
Lemon
Seasoned
Rhinon
Goat
Errors: 45
Rhinon
Cat
Dog
Fish
Errors: 34
Rhinon
Cat
Dog
Fish1
Errors: 1
"""
See the code which gives the desired output without using regex. Indices have been used to get desired data.
lines = data_to_parse.splitlines()
errors_indices = []
i = 0
k = 0
for line in lines: # where Errors: are located are found in saved in list errors_indices.
if 'Errors:' in line:
errors_indices.append(i)
i = i 1
#counter = False
while k < len(errors_indices):
counter = False # It is needed to find the indices when Errors: 0 is hit.
for j in range(errors_indices[k-1], errors_indices[k]):
if 'Errors:' in lines[j]:
lines2 = lines[j].split(':')
lines2_val = lines2[1].strip()
if int(lines2_val) != 0:
print(lines[j])
if int(lines2_val) == 0:
counter = True
elif 'Errors:' not in lines[j] and counter == False:
print(lines[j])
k=k 1
I have tried a few times to see if the code is working properly. It looks it gives the requested output properly. See the output when the code is run as: