I have two lists of tables: old references and new references, I would like to modify this function to save both list in one csv file to get this
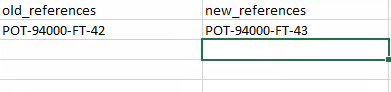
old_references= ["POT-94000-FT-42"]
new_references = ["POT-94000-FT-43"]
headers = ["old_references", "new_references"]
I know how to do it in pandas, unfortunately I don't have access to pandas on the computer. thanks for your advice.
def exportCsv(liste):
date = str(datetime.datetime.now().strftime("%d-%m-%Y %H-%M-%S"))
csv_file = open(os.path.join(sortie, 'increment_reference_{}_'.format(date) '.csv'), 'w')
writer = csv.writer(csv_file)
writer.writerows([liste])
thanks for your advices
CodePudding user response:
In csv.writer you should add the header rows at the start. Other than that what you have looks right.
A clean alternative could be csv.DictWriter which is closer to pandas functionality I feel.
dicts = [
{
"old_references": old,
"new_references": new
}
for new, old in zip(new_references, old_references)
]
with open('test.csv', 'w') as f:
writer = DictWriter(f, list[dicts[0]])
writer.writeheader()
writer.writerows(dicts)
CodePudding user response:
It's not entirely clear what kind of liste object you're using. I think it's worth using the writerow method in your case.
writer.writerow(headers)
writer.writerow([old_references[0], new_references[0]])
Also, do not forget that the file must be closed after the end of reading / writing.
csv_file.close()
In order not to prescribe it explicitly every time, it makes sense to use the with context manager.
date = str(datetime.datetime.now().strftime("%d-%m-%Y %H-%M-%S"))
with open(os.path.join(sortie, 'increment_reference_{}_'.format(date) '.csv'), 'w') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(headers)
writer.writerow([old_references[0], new_references[0]])
In this case, the file will be automatically closed after the end of the context manager.