To start with, I understand that this question has been asked multiple times but I haven't found the solution to my problem.
So, to start with I have used joblib.dump to save a locally trained sklearn RandomForest. I then uploaded this to s3, made a folder called code and put in an inference script there, called inference.py.
import joblib
import json
import numpy
import scipy
import sklearn
import os
"""
Deserialize fitted model
"""
def model_fn(model_dir):
model_path = os.path.join(model_dir, 'test_custom_model')
model = joblib.load(model_path)
return model
"""
input_fn
request_body: The body of the request sent to the model.
request_content_type: (string) specifies the format/variable type of the request
"""
def input_fn(request_body, request_content_type):
if request_content_type == 'application/json':
request_body = json.loads(request_body)
inpVar = request_body['Input']
return inpVar
else:
raise ValueError("This model only supports application/json input")
"""
predict_fn
input_data: returned array from input_fn above
model (sklearn model) returned model loaded from model_fn above
"""
def predict_fn(input_data, model):
return model.predict(input_data)
"""
output_fn
prediction: the returned value from predict_fn above
content_type: the content type the endpoint expects to be returned. Ex: JSON, string
"""
def output_fn(prediction, content_type):
res = int(prediction[0])
respJSON = {'Output': res}
return respJSON
Very simple so far.
I also put this into the local jupyter sagemaker session
all_files (folder) code (folder) inference.py (python file) test_custom_model (joblib dump of model)
The script turns this folder all_files into a tar.gz file
Then comes the main script that I ran on sagemaker:
import boto3
import json
import os
import joblib
import pickle
import tarfile
import sagemaker
import time
from time import gmtime, strftime
import subprocess
from sagemaker import get_execution_role
#Setup
client = boto3.client(service_name="sagemaker")
runtime = boto3.client(service_name="sagemaker-runtime")
boto_session = boto3.session.Session()
s3 = boto_session.resource('s3')
region = boto_session.region_name
print(region)
sagemaker_session = sagemaker.Session()
role = get_execution_role()
#Bucket for model artifacts
default_bucket = 'pretrained-model-deploy'
model_artifacts = f"s3://{default_bucket}/test_custom_model.tar.gz"
#Build tar file with model data inference code
bashCommand = "tar -cvpzf test_custom_model.tar.gz all_files"
process = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)
output, error = process.communicate()
#Upload tar.gz to bucket
response = s3.meta.client.upload_file('test_custom_model.tar.gz', default_bucket, 'test_custom_model.tar.gz')
# retrieve sklearn image
image_uri = sagemaker.image_uris.retrieve(
framework="sklearn",
region=region,
version="0.23-1",
py_version="py3",
instance_type="ml.m5.xlarge",
)
#Step 1: Model Creation
model_name = "sklearn-test" strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print("Model name: " model_name)
create_model_response = client.create_model(
ModelName=model_name,
Containers=[
{
"Image": image_uri,
"ModelDataUrl": model_artifacts,
}
],
ExecutionRoleArn=role,
)
print("Model Arn: " create_model_response["ModelArn"])
#Step 2: EPC Creation - Serverless
sklearn_epc_name = "sklearn-epc" strftime("%Y-%m-%d-%H-%M-%S", gmtime())
response = client.create_endpoint_config(
EndpointConfigName=sklearn_epc_name,
ProductionVariants=[
{
"ModelName": model_name,
"VariantName": "sklearnvariant",
"ServerlessConfig": {
"MemorySizeInMB": 2048,
"MaxConcurrency": 20
}
}
]
)
# #Step 2: EPC Creation - Synchronous
# sklearn_epc_name = "sklearn-epc" strftime("%Y-%m-%d-%H-%M-%S", gmtime())
# endpoint_config_response = client.create_endpoint_config(
# EndpointConfigName=sklearn_epc_name,
# ProductionVariants=[
# {
# "VariantName": "sklearnvariant",
# "ModelName": model_name,
# "InstanceType": "ml.m5.xlarge",
# "InitialInstanceCount": 1
# },
# ],
# )
# print("Endpoint Configuration Arn: " endpoint_config_response["EndpointConfigArn"])
#Step 3: EP Creation
endpoint_name = "sklearn-local-ep" strftime("%Y-%m-%d-%H-%M-%S", gmtime())
create_endpoint_response = client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=sklearn_epc_name,
)
print("Endpoint Arn: " create_endpoint_response["EndpointArn"])
#Monitor creation
describe_endpoint_response = client.describe_endpoint(EndpointName=endpoint_name)
while describe_endpoint_response["EndpointStatus"] == "Creating":
describe_endpoint_response = client.describe_endpoint(EndpointName=endpoint_name)
print(describe_endpoint_response)
time.sleep(15)
print(describe_endpoint_response)
Now, I mainly just want the serverless deployment but that fails after a while with this error message:
{'EndpointName': 'sklearn-local-ep2022-04-29-12-16-10', 'EndpointArn': 'arn:aws:sagemaker:us-east-1:963400650255:endpoint/sklearn-local-ep2022-04-29-12-16-10', 'EndpointConfigName': 'sklearn-epc2022-04-29-12-16-03', 'EndpointStatus': 'Creating', 'CreationTime': datetime.datetime(2022, 4, 29, 12, 16, 10, 290000, tzinfo=tzlocal()), 'LastModifiedTime': datetime.datetime(2022, 4, 29, 12, 16, 11, 52000, tzinfo=tzlocal()), 'ResponseMetadata': {'RequestId': '1d25120e-ddb1-474d-9c5f-025c6be24383', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '1d25120e-ddb1-474d-9c5f-025c6be24383', 'content-type': 'application/x-amz-json-1.1', 'content-length': '305', 'date': 'Fri, 29 Apr 2022 12:21:59 GMT'}, 'RetryAttempts': 0}}
{'EndpointName': 'sklearn-local-ep2022-04-29-12-16-10', 'EndpointArn': 'arn:aws:sagemaker:us-east-1:963400650255:endpoint/sklearn-local-ep2022-04-29-12-16-10', 'EndpointConfigName': 'sklearn-epc2022-04-29-12-16-03', 'EndpointStatus': 'Failed', 'FailureReason': 'Unable to successfully stand up your model within the allotted 180 second timeout. Please ensure that downloading your model artifacts, starting your model container and passing the ping health checks can be completed within 180 seconds.', 'CreationTime': datetime.datetime(2022, 4, 29, 12, 16, 10, 290000, tzinfo=tzlocal()), 'LastModifiedTime': datetime.datetime(2022, 4, 29, 12, 22, 2, 68000, tzinfo=tzlocal()), 'ResponseMetadata': {'RequestId': '59fb8ddd-9d45-41f5-9383-236a2baffb73', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '59fb8ddd-9d45-41f5-9383-236a2baffb73', 'content-type': 'application/x-amz-json-1.1', 'content-length': '559', 'date': 'Fri, 29 Apr 2022 12:22:15 GMT'}, 'RetryAttempts': 0}}
The real time deployment is just permanently stuck at creating.
Cloudwatch has the following errors: Error handling request /ping
AttributeError: 'NoneType' object has no attribute 'startswith'
with traceback:
Traceback (most recent call last):
File "/miniconda3/lib/python3.7/site-packages/gunicorn/workers/base_async.py", line 55, in handle
self.handle_request(listener_name, req, client, addr)
Copy paste has stopped working so I have attached an image of it instead.
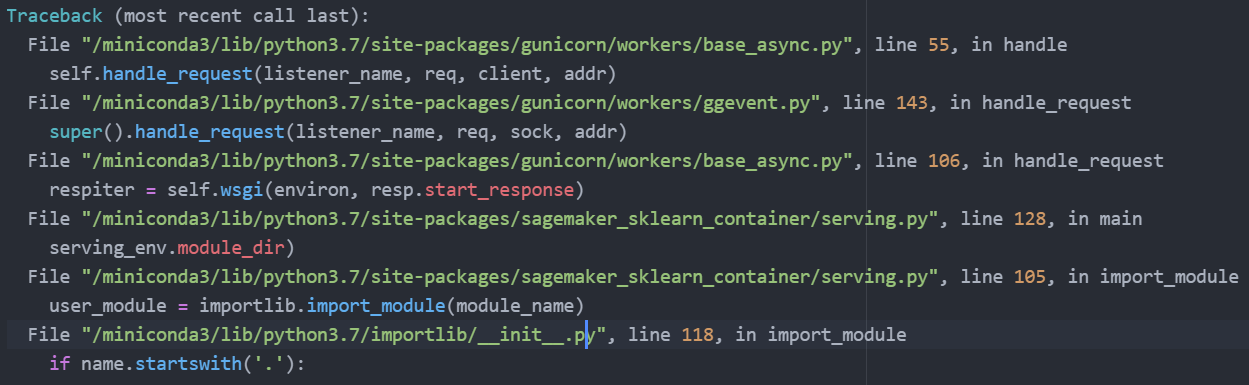
This is the error message I get: Endpoint Arn: arn:aws:sagemaker:us-east-1:963400650255:endpoint/sklearn-local-ep2022-04-29-13-18-09 {'EndpointName': 'sklearn-local-ep2022-04-29-13-18-09', 'EndpointArn': 'arn:aws:sagemaker:us-east-1:963400650255:endpoint/sklearn-local-ep2022-04-29-13-18-09', 'EndpointConfigName': 'sklearn-epc2022-04-29-13-18-07', 'EndpointStatus': 'Creating', 'CreationTime': datetime.datetime(2022, 4, 29, 13, 18, 9, 548000, tzinfo=tzlocal()), 'LastModifiedTime': datetime.datetime(2022, 4, 29, 13, 18, 13, 119000, tzinfo=tzlocal()), 'ResponseMetadata': {'RequestId': 'ef0e49ee-618e-45de-9c49-d796206404a4', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'ef0e49ee-618e-45de-9c49-d796206404a4', 'content-type': 'application/x-amz-json-1.1', 'content-length': '306', 'date': 'Fri, 29 Apr 2022 13:18:24 GMT'}, 'RetryAttempts': 0}}
These are the permissions I have associated with that role:
AmazonSageMaker-ExecutionPolicy
SecretsManagerReadWrite
AmazonS3FullAccess
AmazonSageMakerFullAccess
EC2InstanceProfileForImageBuilderECRContainerBuilds
AWSAppRunnerServicePolicyForECRAccess
What am I doing wrong? I've tried different folder structures for the zip file, different accounts, all to no avail. I don't really want to use the model.deploy() method as I don't know how to use serverless with that, and it's also inconcistent between different model types (I'm trying to make a flexible deployment pipeline where different (xgb / sklearn) models can be deployed with minimal changes.
Please send help, I'm very close to smashing my hair and tearing out my laptop, been struggling with this for a whole 4 days now.
CodePudding user response:
Please follow this guide: https://github.com/RamVegiraju/Pre-Trained-Sklearn-SageMaker. During model creation I think your inference script is not being specified in the environment variables.
CodePudding user response:
I think the issue is with the zipped files. From the question I understood that you are trying to zip up all the files including the model dump and the script.
I would suggest to remove the inference script from the model artifacts.
The model.tar.gz file should consist of only model.
And add the environment variable of inference script as suggested by @ram-vegiraju.
The script should be locally available.