My initial dataframe looks as follows:
import pandas as pd
data = {'document':['abc','abc','abc','abc','xyz','xyz','xyz','test','test','test','test','test','test','test','test','test','stackover','stackover','stackover','stackover','stackover'],
'version':[1,2,3,4,1,2,3,1,2,3,4,5,6,7,8,9,3,4,5,6,7],
'status': [100,100,100,16,200,200,11,11,11,11,15,15,11,15,15,15,10,10,100,15,10]}
df = pd.DataFrame(data)
df
And now I want to add the column 'traffic light'. The conditional formatting of the cells is only for better visualization:
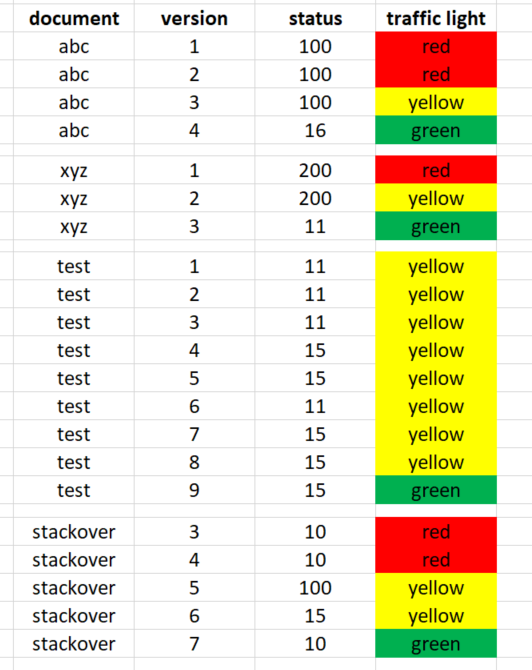
the color of the traffic light comes about as follows:
'status' 100 or 200: This means that the document has been released.
All other 'status' (e.g. 16 or 10): not released
green: the highest document version has to be value 'green'
red: there is a higher version that is released (status 100 or 200).
yellow: there is a higher version that is not released (NOT status 100 or 200).
Can this be implemented directly with the pandas functions or do i need numpy for this? probably the best thing to do is to build in the logic for yellow and red first and then just set the highest version green or?
CodePudding user response:
Try with numpy.select:
import numpy as np
#get maximum version for each document: green
green = df["version"].eq(df.groupby("document")["version"].transform("max"))
#get maximum version for each document with released status: red
red = df["version"].lt(df["document"].map(df[df["status"].isin([100,200])].groupby("document")["version"].max()))
df["traffic light"] = np.select([green, red], ["green", "red"], "yellow")
>>> df
document version status traffic light
0 abc 1 100 red
1 abc 2 100 red
2 abc 3 100 yellow
3 abc 4 16 green
4 xyz 1 200 red
5 xyz 2 200 yellow
6 xyz 3 11 green
7 test 1 11 yellow
8 test 2 11 yellow
9 test 3 11 yellow
10 test 4 15 yellow
11 test 5 15 yellow
12 test 6 11 yellow
13 test 7 15 yellow
14 test 8 15 yellow
15 test 9 15 green
16 stackover 3 10 red
17 stackover 4 10 red
18 stackover 5 100 yellow
19 stackover 6 15 yellow
20 stackover 7 10 green
CodePudding user response:
IIUC, you can use:
# make group
g = df.assign(released=df['status'].isin([100,200])).groupby('document')
# get green values
green = df['version'].eq(g['version'].transform('max'))
# get next release
next_released = g['released'].apply(lambda s: s[::-1].cummax().shift(1, fill_value=False)[::-1])
# select values
import numpy as np
df['traffic light'] = np.select([green, next_released], ['green', 'red'], 'yellow')
output:
document version status traffic light
0 abc 1 100 red
1 abc 2 100 red
2 abc 3 100 yellow
3 abc 4 16 green
4 xyz 1 200 red
5 xyz 2 200 yellow
6 xyz 3 11 green
7 test 1 11 yellow
8 test 2 11 yellow
9 test 3 11 yellow
10 test 4 15 yellow
11 test 5 15 yellow
12 test 6 11 yellow
13 test 7 15 yellow
14 test 8 15 yellow
15 test 9 15 green
16 stackover 3 10 red
17 stackover 4 10 red
18 stackover 5 100 yellow
19 stackover 6 15 yellow
20 stackover 7 10 green