I need to preprocess a column for machine learning in python. The column contains a series of 1s and 0s (which is the desired output), but there are some strings in there that needs to be removed ['PX7','D1', etc..]
I thought about using df.replace to replace the strings with np.nan and then using df.dropna() to remove it. I was wondering what is the standard way of doing this given that this is probably a very common preprocessing task.
CodePudding user response:
You can use:
df2 = df.where(df.isin([0,1]))
Or, convert to numeric to keep all numbers:
df2 = df.apply(pd.to_numeric, errors='coerce')
Then you can use dropna the way you want (if needed).
CodePudding user response:
Use:
df[df['col'].str.isdigit().fillna(True)]
Input:
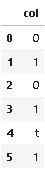
Output:
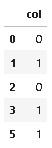
Second approch:
df[df['col'].isin([0,1])]