I am trying to filter a pandas DataFrame with a specific condition.
import pandas as pd
df = pd.DataFrame({
'name': ['A','A','C','C','E','E'],
'cat': [1, 1, 1, 0, 2, 3]
})
I'd like to filter by cat == 1. df[df['cat'] == 1]
However, if 1 doesn't exist as a cat for a name, then get the first cat. In this case, A and C will be filtered by 1, for E, it would be 2.
Expected output:
name cat
A 1
C 1
E 2
Second part to this question:
I have additional columns that need to be retained in the DataFrame.
df = pd.DataFrame({
'name': ['A','A','C','C','E','E'],
'lbl': ['z','z','y','y','u','u'],
'cat': [1, 1, 1, 0, 2, 3],
'val1': [10, 20, 5, 10, 10, 0],
'yr': [90, 91, 90, 90, 90, 90]
})
The categorical variables will be part of the groupby, however, for numerical variables, I need to apply statistical functions / aggregations. mean for val1 and mode for yr.
Expected output:
name lbl cat val1 yr
A z 1 15 90
C y 1 5 90
E u 2 10 90
If there is a tie in mode, as is for rows with name A, select the first value.
CodePudding user response:
First we group based on the name column, Then we apply a lambda function that check the values of the cat column for each group if there is a 1 there or it will return the first value of the group. Use:
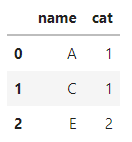
df.groupby('name')['cat'].apply(lambda x: 1 if 1 in x.values else x.values[0]).reset_index()
Output:
CodePudding user response:
Another version:
out = df.sort_values(
"cat", kind="stable", key=lambda x: x != 1
).drop_duplicates("name")
print(out)
Prints:
name cat
0 A 1
2 C 1
4 E 2
CodePudding user response:
You can groupby name column then apply a customized function to get desired rows from each group.
out = (df.groupby('name')
.apply(lambda g: g[g['cat'].eq(1)] if g['cat'].eq(1).any() else g.head(1))
.reset_index(drop=True))
print(out)
name cat
0 A 1
1 C 1
2 E 2