Im trying to define a regexp to remove some carriage return in a file to be loaded into a DB.
Here is the fragment
200;GBP;;"";"";"";"";;;;"";"";"";"";;;"";1122;"BP JET WASH IP2 9RP
";"";Hamilton;"";;0;0;0;1;1;"";
This is the regexp I used in 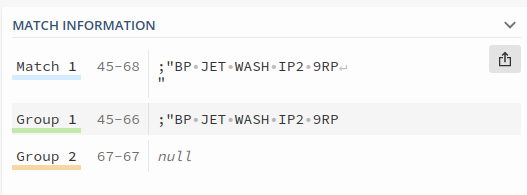
But the result is wrong, because it still introduce an invisible new line as follow
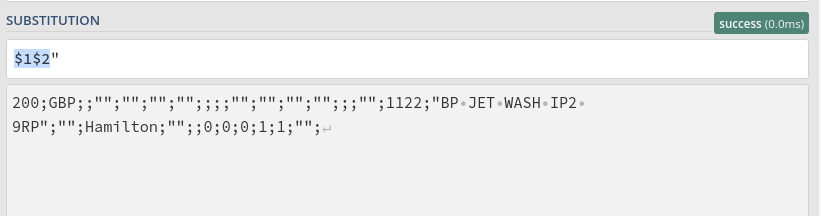
I also try to use sed but the result is exactly the same.
So, the question is: Where am I wrong?
CodePudding user response:
perl -MText::CSV_XS=csv -wE'csv(in=>csv(in=>shift,sep=>";",on_in=>sub{s/\n $// for@{$_[1]}}))' file.csv
will remove trailing newlines from every field in the CSV (with sep ;) and spit out correct CSV (with sep ,). If you want ; in to output too, use
perl -MText::CSV_XS=csv -wE'csv(in=>csv(in=>shift,sep=>";",on_in=>sub{s/\n $// for@{$_[1]}}),sep=>";")' file.csv
CodePudding user response:
It's usually best to use an existing parser rather than writing your own.
I'd use the following Perl program:
perl -MText::CSV_XS=csv -e'
csv
in => *ARGV,
sep => ";",
blank_is_undef => 1,
quote_empty => 1,
on_in => sub { s/\n//g for @{ $_[1] }; };
' old.csv >new.csv
Output:
200;GBP;;"";"";"";"";;;;"";"";"";"";;;"";1122;"BP JET WASH IP2 9RP";"";Hamilton;"";;0;0;0;1;1;"";
If for some reason you want to avoid XS, the slower Text::CSV is a drop-in replacement.
CodePudding user response:
sed is line based. It's possible to achieve what you want, but I'd rather use a more suitable tool. For example, Perl:
perl -pe 's/\n/<>/e if tr/"// % 2 == 1' file.csv
-preads the input line by line, running the code for each line before outputting it;- The
/eoption interprets the replacement in a substitution as code, in this case replacing the final newline with the following line (<>reads the input) tr/"//in numeric context returns the number of matches, i.e. the number of double quotes;- If the number is odd, we remove the newline (
%is the modulo operator).
The corresponding sed invocation would be
sed '/^\([^"]*"[^"]*"\)*[^"]*"[^"]*$/{N;s/\n//}' file.csv
- on lines containing a non-paired double quote, read the next line to the pattern space (
N) and remove the newline.
Update:
perl -ne 'chomp $p if ! /^[0-9] ;/; print $p; $p = $_; END { print $p }' file.csv
This should remove the newlines if they're not followed by a number and a semicolon. It keeps the previous line in the variable $p, if the current line doesn't start with a number followed by a semicolon, newline is chomped from the previous line. The, the previous line is printed and the current line is remembered. The last line needs to be printed separately as there's no following line for it to make it printed.