I have the following dataframe of students with their exam scores in different dates:
df = pd.DataFrame({'student': 'A A A B B B B'.split(),
'exam_date': pd.date_range(start='1/1/2020', periods=7, freq='M'),
'score': [15, 28, 17, 22, 43, 40, 52]})
print(df)
student exam_date score
0 A 2020-01-31 15
1 A 2020-02-29 28
2 A 2020-03-31 17
3 B 2020-04-30 22
4 B 2020-05-31 43
5 B 2020-06-30 40
6 B 2020-07-31 52
I need to create a new column -- the slope of scores of each student.
I'm trying the following script:
df.exam_date = pd.to_datetime(df.exam_date)
df['date_ordinal'] = pd.to_datetime(df['exam_date']).map(dt.datetime.toordinal)
slope, intercept, r_value, p_value, std_err = scipy.stats.linregress(df['date_ordinal'], df['score'])
What would be the smartest way of doing it? Any suggestions would be appreciated. Thanks!
Desired output:
student exam_date score slope
0 A 2020-01-31 15 0.028
1 A 2020-02-29 28 0.028
2 A 2020-03-31 17 0.028
3 B 2020-04-30 22 0.285
4 B 2020-05-31 43 0.285
5 B 2020-06-30 40 0.285
6 B 2020-07-31 52 0.285
CodePudding user response:
You can use a groupby / apply pattern to compute the slope for each student in one call, and then use merge or join to attach back onto your original dataframe.
Step 1: Define function to compute slope for each student You have essentially already done this in your question:
import pandas as pd
from scipy import stats
def get_slope(df_student):
"""
Assumes df_student has the columns 'score' and 'date_ordinal' available
"""
results = stats.linregress(df_student['date_ordinal'], df_student['score'])
return results.slope
Step 2: Compute the slope for each student with groupby
slopes = df.groupby('student').apply(get_slope).rename('slope')
slopes object is a series indexed by student:
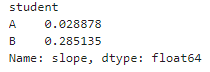
Step 3: Join back to original dataframe
Here we can either use join or merge. The main difference between join and merge is that merge is more flexible with the ability to join on both row indexes and columns, while join is more concise and designed to join in row indexes only. To use join here, the index of the original dataframe would need to change to student. So instead, use the merge method:
df_final = df.merge(slopes, left_on=['student'], right_index=True).drop('date_ordinal', axis=1)
Now df_final should be your desired output:
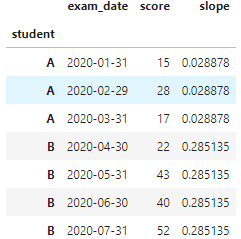
Notes:
You can achieve the same result more concisely if you are willing to use student as the index of your original dataframe as follows:
df = pd.DataFrame({'student': 'A A A B B B B'.split(),
'exam_date': pd.date_range(start='1/1/2020', periods=7, freq='M'),
'score': [15, 28, 17, 22, 43, 40, 52]})
df['date_ordinal'] = pd.to_datetime(df['exam_date']).map(dt.datetime.toordinal)
df.set_index(['student'], inplace=True, append=False)
df['slope'] = df.groupby('student')\
.apply(lambda x: stats.linregress(x['date_ordinal'], x['score']).slope)\
.drop('date_ordinal', axis=1)