So i have the following line of code.
df[['Steps','CampaignSource','UserId']].groupby(['Steps','CampaignSource']).apply(lambda x : x.nunique() if x.name[0] != '9.2-Finalizado' else x.count())
Which as can see i apply a condition based on a groups key specifically the first one. But the thing is i get this weird end result, which basically gives me two more columns than i would like.
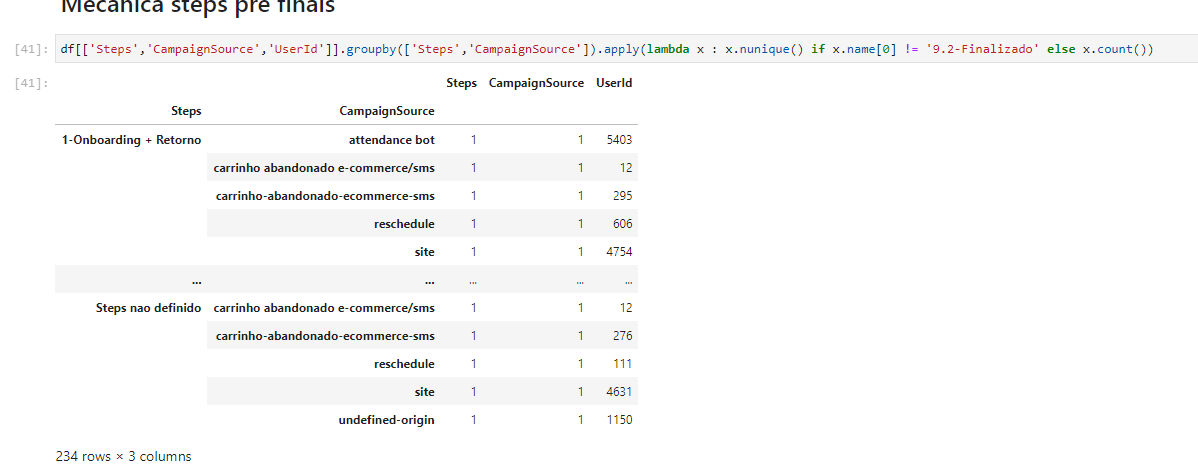
Any clues on the why, i would like that only UserId returns. if necessary i can provide a sample df.
CodePudding user response:
You can slice the GroupBy object:
(df.groupby(['Steps','CampaignSource'])['UserId']
.apply(lambda x : x.nunique() if x.name[0] != '9.2-Finalizado' else x.count())
)
or for a DataFrame:
(df.groupby(['Steps','CampaignSource'])[['UserId']]
.apply(lambda x : x.nunique() if x.name[0] != '9.2-Finalizado' else x.count())
)
CodePudding user response:
If you are asking for the reason why you are seeing the 2 additional columns, it is because you are applying the lambda function over all the 3 columns (Steps, CampaignSource, UserId), and performing a nunique() operation. This would return a 1 for both Steps and CampaignSource columns because they have 1 unique record each.