I have a df, sample data looks like below:
df
user collaborators
A {'first_name' : 'jack', 'last_name' : 'abc', 'id' : '[email protected]'}, {'first_name' : 'john', 'last_name' : 'pqr', 'id' : '[email protected]'}
B {'first_name' : 'tom', 'last_name' : 'pwc', 'id' : '[email protected]'}
C {'first_name' : 'jill', 'last_name' : 'def', 'id' : '[email protected]'}, {'first_name' : 'jill', 'last_name' : 'def', 'id' : '[email protected]'}
I need to get the first_name, last_name and id in individual columns.
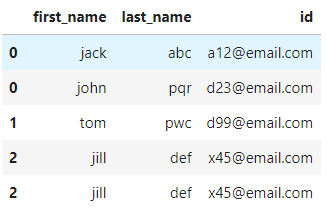
Expected Output:

I first tried to remove the square brackets using:
df['collaborators'].str.strip('{}')
df['collaborators'].str.replace('[{}]', '')
But I got only NaN as the result, not sure why. I thought of exploding the column after converting it to a list and extracting first_name, last_name and id. But all this looks like lot of steps. Could someone please let me know if there's a shorter way.
Updated DF:

I used to_list to convert the three columns into list:
df['first_name'] = df['first_name'].to_list()
df['last_name'] = df['last_name'].to_list()
df['id'] = df['id'].to_list()
I then tried below code from SO:
df.set_index('collaborators').apply(lambda x:
x.apply(pd.Series).stack()).reset_index().drop('level_1', 1)
But it didn't work for me.
CodePudding user response:
Use ast.literal_eval with add [] for lists of DataFrames, so possible use