Summary I have a csv file as a datasource which I am loading into a pandas dataframe. It contains a column for datetime including timestamp and spans a history of multiple months, automatically created when someone performs different scanning actions with a machine. The type of action is also recorded in a seperate column:
| Index | Datetime | Action |
|---|---|---|
| 0 | 12/7/2021 16:39:46 | a |
| 1 | 16/6/2021 10:24:26 | a |
| 2 | 21/6/2021 12:43:35 | b |
| 3 | 11/6/2021 19:56:28 | a |
| 4 | 28/5/2021 14:28:47 | b |
Problem To plot a type of heatmap and find out when over the day actions are clustered, I wanted to isolate the timestamp from the Datetime, because I don't really care about the date.
Datetime was initially an object, I converted it to datetime using pd.to.datetime.
Now I was able to split the time to a different column, using:
df['Time'] = df['Timestamp'].dt.strftime('%H:%M')
But my problem is, the new dtype is an object again and for plotting reasons I think I have to convert it again in order to sort it correctly.
Final output should be the mentioned heatmap with the x-axis ranging from 06:00 AM to 23:00 AM, plotting the different actions types in two buckets on the y-axis. Just so you are aware of the final use of the data.
I'll be really thankful for any pointers for someone new to time series analysis with python pandas :)
CodePudding user response:
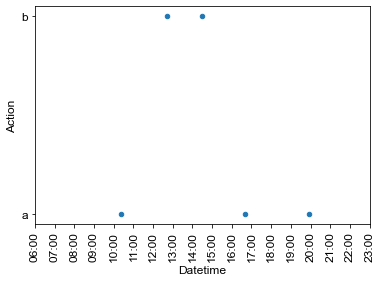
I think you're looking for a scatter chart and not a heatmap. Try:
import matplotlib.pyplot as plt
import matplotlib.dates as md
df["Datetime"] = pd.to_datetime(pd.to_datetime(df["Datetime"], format="%d/%m/%Y %H:%M:%S").dt.strftime("%H:%M"))
ax = df.plot.scatter(x="Datetime",y="Action",rot=90)
ax.set_xlim(pd.Timestamp("06:00"), pd.Timestamp("23:00"))
ax.xaxis.set_major_locator(md.MinuteLocator(byminute = [0]))
ax.xaxis.set_major_formatter(md.DateFormatter('%H:%M'))
Output: