With the following data frame:
dta <- structure(list(sociodemographic_var = structure(c(3L, 6L, 7L,
8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 18L, 19L, 20L, 21L, 22L,
23L, 24L, 26L, 18L, 20L, 21L, 26L, 13L, 16L, 21L, 22L, 26L, 26L,
9L, 13L, 17L, 18L, 20L, 21L, 23L, 26L, 20L, 26L), levels = c("1st grade",
"2nd grade", "3rd grade", "4th grade", "5th grade", "6th grade",
"7th grade", "8th grade", "9th grade", "10th grade", "11th grade",
"12th grade, no diploma", "High school graduate", "GED or equivalent",
"Some college, no degree", "Less than 1 year of college credit/post-secondary education (or less than 10 classes)",
"One year or more of college credit, no degree", "Associate degree: Occupational, Technical, or Vocational",
"Associate degree: Academic Program", "Bachelor's degree (ex. BA, AB, BS, BBS)",
"Master's degree (ex. MA, MS, MEng, MEd, MBA)", "Professional School degree (ex. MD, DDS, DVN, JD)",
"Doctoral degree (ex. PhD, EdD)", "Refused to answer", "Don't Know",
"unknown"), class = "factor"), event = structure(c(1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L,
3L, 3L, 3L, 3L, 5L, 5L, 5L, 5L, 5L, 7L, 9L, 9L, 9L, 9L, 9L, 9L,
9L, 9L, 11L, 11L), levels = c("Baseline", "0.5 Year", "1 Year",
"1.5 Year", "2 Year", "2.5 Year", "3 Year", "3.5 Year", "4 Year",
"4.5 Year", "5 Year", "5.5 Year", "6 Year", "Screener"), class = "factor"),
visit_type = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L), levels = c("on-site", "hybrid", "remote", "unknown"), class = "factor"),
n = c(2L, 13L, 5L, 9L, 15L, 18L, 26L, 25L, 192L, 27L, 485L,
224L, 183L, 1011L, 666L, 55L, 78L, 3L, 9L, 1L, 1L, 2L, 208L,
1L, 1L, 1L, 1L, 126L, 28L, 1L, 1L, 2L, 2L, 3L, 4L, 1L, 543L,
1L, 300L)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-39L))
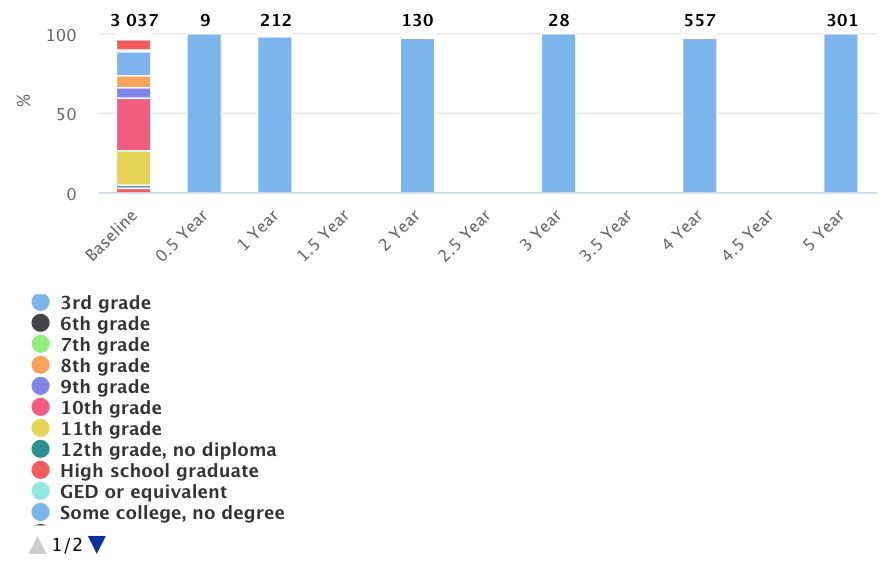
I would assume that, generating a highcharter bar plot with:
library(highcharter) # v0.9.4
dta |>
hchart(type = "column", hcaes(x = "event", y = "n", group = "sociodemographic_var")) |>
hc_yAxis(title = list(text = "%"), max = 115, endOnTick = FALSE, stackLabels = list(enabled = TRUE)) |>
hc_xAxis(title = "") |>
hc_plotOptions(series = list(stacking = "percent"))
the xAxis would be ordered by levels(dta$event):
levels(dta$event)
[1] "Baseline" "0.5 Year" "1 Year" "1.5 Year" "2 Year" "2.5 Year" "3 Year" "3.5 Year" "4 Year" "4.5 Year" "5 Year" "5.5 Year"
[13] "6 Year" "Screener"
But the ordering is different and neither alphabetical nor based on the total number of values:
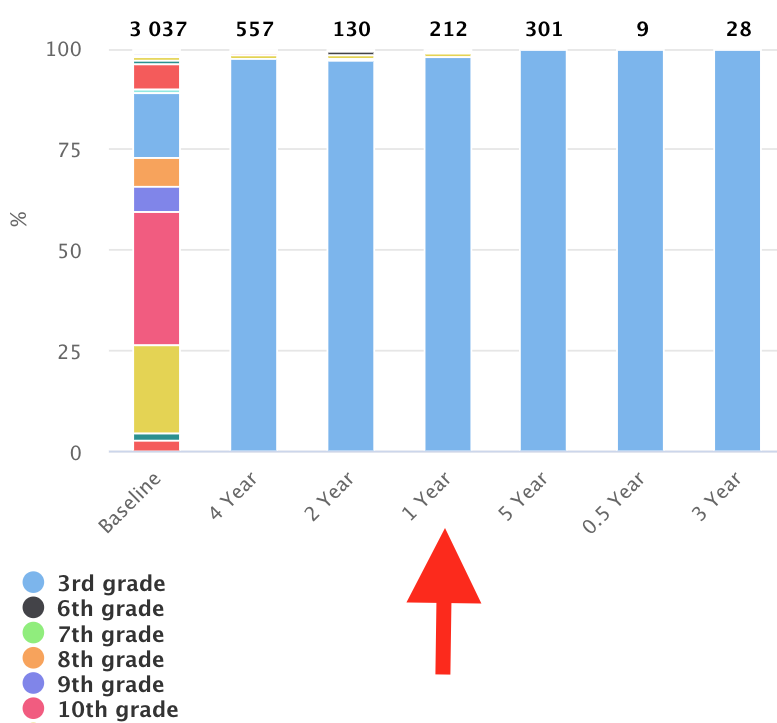
I am interested to understand why it's the case and how to set the order right.
CodePudding user response:
You can add categories to your hc_xAxis to make an order like this:
library(highcharter)
dta |>
hchart(type = "column", hcaes(x = "event", y = "n", group = "sociodemographic_var")) |>
hc_yAxis(title = list(text = "%"), max = 115, endOnTick = FALSE, stackLabels = list(enabled = TRUE)) |>
hc_xAxis(title = "", categories = levels(dta$event)) |>
hc_plotOptions(series = list(stacking = "percent"))
Output: