I have a set of data of 2000 people with repeated measurements over multiple years between 2000-2022 (some people have data for the full time period whereas others only for a subset of these years). Within a single year, each person can only fall into one of four groups: 0, 1, 2, or 3. I want to quantify how many times each person changes grouping within their individual sampling period. The data is laid out like this (image attached):
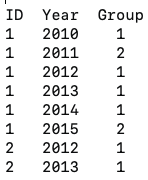
So for this example dataset, the code would tell me that person 1 has had 3 changes (from group 1 to group 2 in 2011, then from group 2 back to group 1 and lastly back to group 2 in 2015) whereas for group 1 the code should tell me there have been 0 changes.
I don't need the loop to tell me which years have the changes for now, only the total amount of changes in grouping per person. I was thinking about a loop that goes something like "if X does not equal previous number then add 1 to a count" but I've never done something like this before and not quite sure how to lay this code out.
Would appreciate any help :)
Edit: This is the R syntax version of the data as suggested by @GregorThomas
structure(list(ID = c(1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2,
2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4), Year = c(2010,
2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021,
2001, 2002, 2003, 2004, 2001, 2002, 2003, 2004, 2005, 2007, 2009,
2010, 2011, 2012, 2013, 2014, 2015, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016,
2017, 2018, 2019, 2020, 2021), Culture_Grouping = c(1, 1, 1,
1, 1, 1, 3, 3, 3, 1, 3, 3, 0, 1, 3, 3, 3, 3, 3, 3, 3, 0, 0, 0,
0, 0, 2, 0, 0, 1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1)), row.names = c(NA, -50L), class = c("tbl_df",
"tbl", "data.frame"))
CodePudding user response:
You can achieve it without any loop:
aggregate(Group ~ ID, df, \(x) sum(diff(x) != 0))
# ID Group
# 1 1 3
# 2 2 0
Its dplyr equivalent is:
library(dplyr)
df %>%
group_by(ID) %>%
summarise(Group = sum(diff(Group) != 0)) %>%
ungroup()
Or more simplified with count():
df %>%
count(ID, wt = diff(Group) != 0)
Data
df <- data.frame(ID = c(rep(1, 6), rep(2, 2)),
Year = c(2010:2015, 2012:2013),
Group = c(1,2,1,1,1,2,1,1))
CodePudding user response:
data.table option:
library(data.table)
setDT(df)[, uniqueN(rleid(Culture_Grouping)) - 1, ID]
Output:
ID V1
1: 1 3
2: 2 2
3: 3 3
4: 4 2